В настоящее время данные оказываются мощной движущей силой различных отраслей. Крупные компании, представляющие различные сферы торговли, стремятся использовать полезную ценность данных.
Таким образом, данные стали очень важным инструментом для тех, кто готов принимать выгодные решения, касающиеся бизнеса. Более того, тщательный анализ огромного количества данных позволяет влиять или, скорее, манипулировать решениями клиентов. Для этой цели используются многочисленные потоки информации, а также каналы связи.
Сфера ритейла стремительно развивается. Ритейлерам удается анализировать данные и разрабатывать своеобразный психологический портрет покупателя. Таким образом, покупатель, как правило, легко подвержен влиянию хитростей, которые разработаны ритейлерами.
Типичные задачи, встречающиеся в сфере ритейла:
- Увеличение трафика - количества покупателей
- Уменьшение оттока клиентов
- Увеличение среднего чека
- Разработка программ лояльности
- Определение скидки
- Выбор нового места для торговой точки в зависимости от района города, арендной платы, близости бизнес-центров, конкурентов и др.
- Сравнение точек продаж по доходу на квадратный метр и др.
Рассмотрим типичный кейс на примере сети ресторанов быстрого питания.
Задачи, которые необходимо решить:
- Выделить сегменты клиентов, построить портреты клиентов, которые регулярное посещают рестораны
- Произвести оценку времени жизни, то есть как долго клиент будет посещать, совершать заказы в ресторане фаст фуд
- Разработать программу лояльности
Какими данными мы оперируем в этом кейсе?
У нас имеются данные чеков: id-заказа, дата заказа, время заказа, какие товары или услуги клиент приобрел (наименование, группа, количество, сумма), тип оплаты – наличными или банковской картой, гео-привязка – адрес, куда доставляется, тип помещения (жилое, не жилое) и данные CRM системы, показатель RFM.
Первый этап анализа – это подготовка данных: загрузка и преобразование в формат, который понимается алгоритмами интеллектуального анализа данных.
Кроме того, необходимо подготовить два набора данных, каждый из которых соответствует одной из следующих двух задач: обучающие данные, тестовые данные.
Обучающие данные: последние данные клиентов, которые используются в качестве учебных данных. Алгоритм работает с этим типом данных.
Тестовые данные: последние данные клиента, которые используются в качестве скоринговых данных. Подготовленная модель применяется к выбранным данным для оценки прогнозируемой целевой переменной.
Этапы построения модели:
- Сегментация клиентов с помощью кластеризации методом к- средних
- Лояльность клиентов с помощью деревьев принятия решений
- Жизненный цикл клиентов с помощью обобщённых моделей регрессии
- Построение профилей клиентов с помощью метода опорных векторов и деревьев принятия решений
В сегментации клиентов бизнес проблема заключается в том, чтобы сгруппировать клиентов в однородные группы на основе демографических данных клиентов, истории покупок и других атрибутов.
Бизнес-аналитики смогут анализировать каждый сегмент, чтобы лучше понять группу клиентов, обнаруженную моделью, и назвать каждый сегмент.
Клиенты группируются с использованием алгоритма кластеризации к-средние. Открытые правила кластеризации определяют профиль клиентов.
В модели лояльности бизнес проблема заключается в создании профиля клиентов, чтобы объяснить влияние характеристик клиентов на их лояльность к компании.
Используя методы добычи данных, KPI моделируются с использованием дерева решений.
Этот анализ определяет, какие ключевые атрибуты клиента влияют на его лояльность к компаниям.
В моделировании жизненного цикла клиентов бизнес проблема заключается в том, чтобы идентифицировать / прогнозировать клиентов, которые могут представлять наибольшую ценность для перевозчика в течение своего жизненного цикла, на основе таких критериев, как демографическая информация клиента, история посещения заведения, качество обслуживания и другие.
В этом анализе определяются ключевые атрибуты клиента, влияющие на ценность жизненного цикла.
Значение времени жизни – это непрерывное значение (общий доход, внесенный клиентом).
Значение жизненного цикла преобразуется в категориальные значения, используя стандартные операции биннинга.
Категориальные переменные моделируются как модель классификации для определения или прогнозирования влияния различных независимых переменных (атрибутов) на зависимую целевую переменную (KPI - категориальную).
Используя методы добычи данных, целевые переменные, категориальное значение жизненного цикла и время выживания моделируются с использованием алгоритма классификации, дерева решений.
Продолжительность непрерывного жизненного цикла и время выживания моделируются как модели регрессии с использованием алгоритма обобщенной линейной модели регрессии.
Модели добычи данных разрабатываются каждый месяц с использованием последних данных клиентов, и применяются к данным текущих базовых клиентов, чтобы предсказать, какой клиент, вероятно, будет представлять наибольшую ценность в течение срока жизненного цикла.
Кейс разбирается на курсах Академии Анализа Данных:
https://edu.softline.ru/vendors/data_academy/vvedenie-v-analiz-dannyh-i-dejta-sajns-v-python
RFM анализ для сегментации клиентов
Хорошие маркетологи понимают важность фразы «знай своего клиента». Вместо того, чтобы просто сосредоточиться на создании большего количества кликов, маркетологи должны следовать смене парадигмы от увеличения CTR (переходов по кликам) до удержания, лояльности и построения отношений с клиентами.
Вместо того, чтобы анализировать всю клиентскую базу в целом, лучше разбить их на однородные группы, понять особенности каждой группы и привлечь их к соответствующим кампаниям, а не по возрасту или географии клиентов.
RFM-анализ - один из самых популярных, простых в использовании и эффективных методов сегментации, позволяющий маркетологам анализировать поведение клиентов.
Что такое RFM анализ?
RFM означает «Recency», «Frequency» и «Monetary», каждое из которых соответствует некоторой ключевой характеристике клиента. Эти метрики RFM являются важными индикаторами поведения клиента, потому что частота и денежная стоимость влияют на стоимость жизни клиента, а давность влияет на удержание, меру вовлеченности.
Компании, которые не имеют денежного аспекта, такие как зрительская аудитория, читательская аудитория или продукты, ориентированные на серфинг, могут использовать параметры вовлечения вместо монетарных факторов.
Это приводит к использованию RFE - вариация RFM. Кроме того, этот параметр Engagement может быть определен как составное значение на основе таких показателей, как отказы, продолжительность посещения, количество посещенных страниц, время, потраченное на страницу и т. д.
Факторы RFM иллюстрируют:
- чем более поздняя покупка, тем более отзывчивым является покупатель
- чем чаще покупатель делает покупки, тем больше он заинтересован и доволен
- денежная стоимость отличает тех, кто много тратит, от покупателей с низкой стоимостью
Как реализовать анализ RFM, используемый в сегментации клиентов
RFM-анализ помогает маркетологам найти ответы на следующие вопросы:
- Кто ваши лучшие клиенты?
- Кто из ваших клиентов может внести свой вклад в ваш показатель оттока?
- У кого есть потенциал стать ценными клиентами?
- Кто из ваших клиентов может быть сохранен?
- Кто из ваших клиентов с наибольшей вероятностью отреагирует на рекламные кампании
Давайте продемонстрируем, как работает RFM, рассмотрев примерный набор данных по транзакциям клиентов:
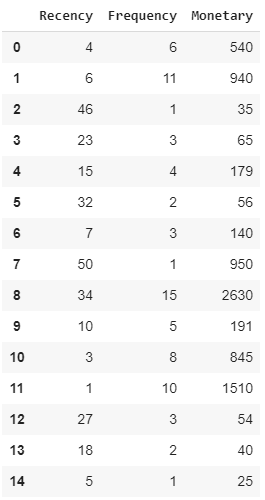
Таблица 1: Пример набора данных транзакций клиента
Таблица 1 содержит значения давности, частоты и денежных показателей для 15 клиентов на основе их транзакций.
Пример анализа RFM в Python
Чтобы провести анализ RFM для этого примера, давайте посмотрим, как мы можем оценивать этих клиентов, ранжируя их на основе каждого атрибута RFM в отдельности.
Шаг 1. Подключение необходимых библиотек.
Шаг 2. Выгрузка данных из таблицы excel.

Таблица имеет вид:
Предположим, что мы оцениваем этих клиентов от 1 до 5, используя значения RFM.
Для этого будем использовать квантили. Каждый квинтиль содержит 20% населения. Использование квинтилей является более гибким, поскольку диапазоны будут адаптироваться к данным и работать в разных отраслях или в случае каких-либо изменений в ожидаемом поведении клиентов.
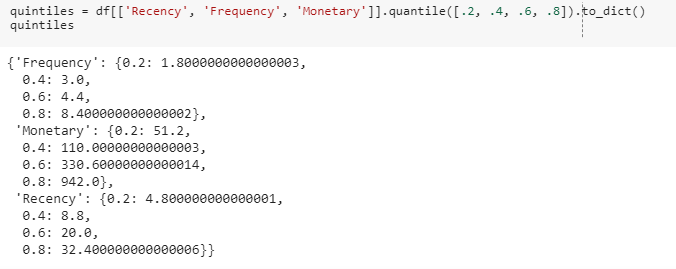
Шаг 3. Получим квинтили для каждого параметра.
Шаг 4. Далее необходимо написать функции присвоения рангов от 1 до 5. Чем меньше значение Recency, тем лучше, для значений Frequency и Monetary наоборот.

Шаг 5. Проведем ранжирование для значений Recency, Frequency, Monetary и занесем значения в отдельные столбцы.

Ниже представлена таблица с распределенными рангами.
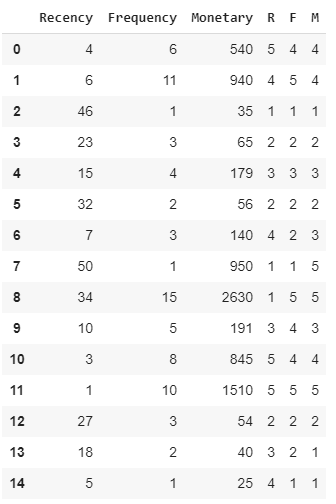
RFM Score
Наконец, мы можем ранжировать этих клиентов, комбинируя их индивидуальные рейтинги R, F и M, чтобы получить агрегированную оценку RFM. Эта оценка RFM, показанная в таблице ниже, является просто средним значением отдельных оценок R, F и M, полученным путем присвоения равных весов каждому атрибуту RFM.
Шаг 6. Получение RFM оценки.

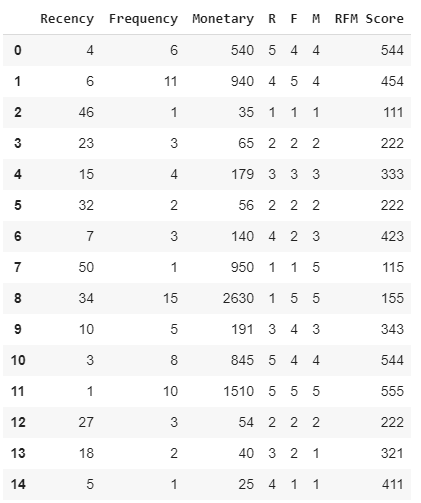
Результаты RFM дают нам 53 =125 сегментов. С таким количеством сегментов работать неудобно, поэтому выделим несколько. Сделаем разбивку, основанную на оценках R и F.
Ниже представлено описание сегментов:
|
Сегмент |
Описание |
|
Чемпионы |
Купили недавно, покупают часто и тратят больше всего |
|
Постоянные клиенты |
Покупают на регулярной основе. Отзывчивы к акциям. |
|
Потенциальный лоялист |
Последние клиенты со средней частотой. |
|
Последние клиенты |
Купили совсем недавно, но делают это не часто. |
|
Перспективные клиенты |
Последние клиенты, но много не потратили. |
|
Клиенты, нуждающиеся во внимании |
Выше среднего показатели давности, частоты и денежных затрат. Возможно, давно не совершал покупок. |
|
Засыпающие |
Ниже среднего давность и частота. Потеряем их, если не реактивировать. |
|
В зоне риска |
Покупали часто, но давно. Необходимо вернуть их! |
|
Не можем потерять их |
Покупают часто, но не вернулся в течение длительного времени. |
|
Бездействие |
Последняя покупка была давно и небольшое число заказов. Можем потерять |
Полученная матрица выглядит так:
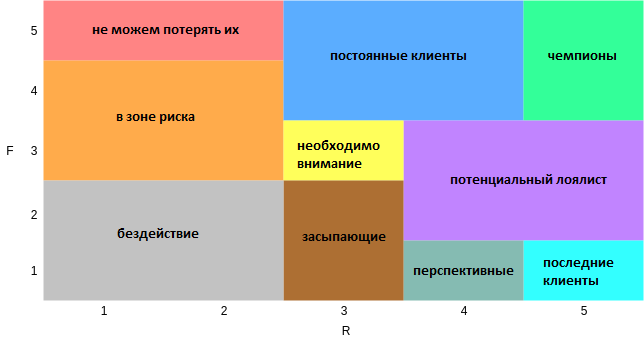
Как показано в приведенной выше матрице RFM, мы можем получить следующую информацию для каждого из сегментов:
- краткое описание сегмента
- последние (последнее действие)
- частота (подсчет активности)
- средняя денежная стоимость
- достижимость пользователей по разным каналам
Шаг 7. Делаем разбивку по сегментам.

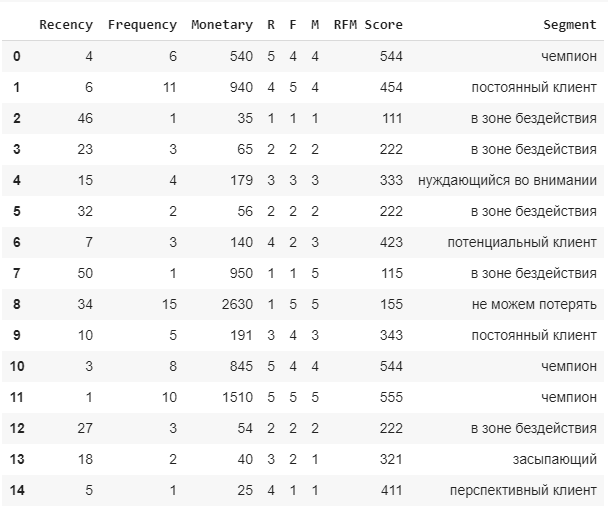
В этом примере сегментация сделана таким образом. Вы можете выделять группы по своим характеристикам. Это неоднозначная реализация.
Визуально посмотрим как комбинированная оценка RFM распределена для R, F и M.
1. Распределение для показателя Monetary.

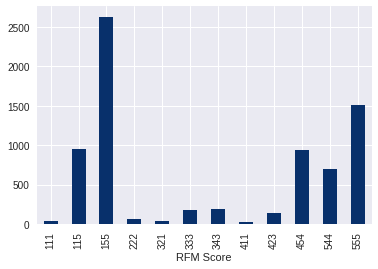
Из графика видно, что клиенты из сегмента «Не можем потерять» и «Чемпионы» совершают покупки на большую сумму, чем все остальные категории.
2. Распределение для показателя Frequency.

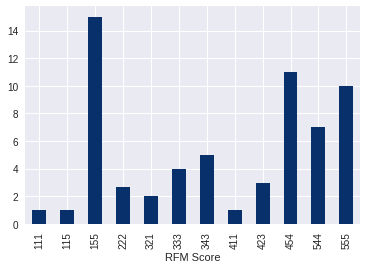
Из графика видно, что клиенты из сегмента «Не можем потерять», «Чемпионы» и «Постоянные клиенты» имеют самый высокий показатель Frequency.
3. Распределение для показателя Recency.

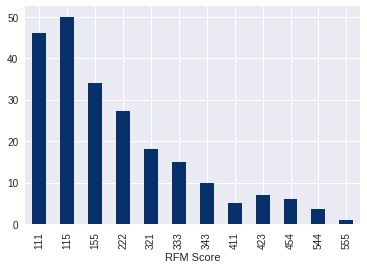
Из графика видно, что клиенты из сегмента «В зоне бездействия», «Не можем потерять» имеют высокий показатель Recency. Эти клиенты давно совершали покупки и необходимо применять меры для пробуждения интереса, может быть заинтересовать акциями или скидками.
Последние данные, частота и денежный анализ
Следующий вопрос, который возникает: справедливо ли усреднять индивидуальные оценки R, F и M для каждого клиента и назначать их сегменту RFM согласно их поведению при покупке или взаимодействии?
В зависимости от характера вашего бизнеса вы можете увеличить или уменьшить относительную важность каждой переменной RFM для получения окончательного результата. Например:
- В бизнесе потребительских товаров длительного пользования денежная стоимость каждой транзакции обычно высока, но частота и актуальность низкие. Например, вы не можете ожидать, что клиент будет покупать холодильник или кондиционер ежемесячно. В этом случае маркетолог мог бы придать больший вес денежным аспектам и аспектам давности, а не частотному аспекту.
- В розничном бизнесе, торгующем модой / косметикой, клиент, который ищет и покупает продукты каждый месяц, будет иметь более высокую оценку давности и частоты, чем денежная оценка. Соответственно, показатель RFM можно рассчитать, придав больший вес показателям R и F, чем M.
- Для контентных приложений, таких как Hotstar или Netflix, наблюдатель разгула будет иметь более длительную продолжительность сеанса, чем основной потребитель, наблюдающий с регулярными интервалами. Для связующих можно было бы придать большее значение вовлеченности и частоте, чем давности, а для главных участников, давности и частоте могут быть приданы более высокие веса, чем вовлеченности, чтобы получить оценку RFE.
Этот простой подход к масштабированию клиентов от 1 до 5 приведет к не более 125 различным оценкам RFM (5x5x5), варьирующимся от 111 (самый низкий) до 555 (самый высокий). Каждая ячейка RFM будет отличаться по размеру и отличаться друг от друга с точки зрения ключевых привычек клиента, отраженных в баллах RFM. Очевидно, что маркетологи не могут анализировать все 125 сегментов по отдельности, если каждая ячейка RFM считается сегментом, и визуализировать этот воображаемый трехмерный куб сложно и непросто!
В целом денежный аспект RFM рассматривается как показатель агрегирования для суммирования транзакций или общей продолжительности посещения. Таким образом, эти 125 сегментов RFM сокращаются до 25 сегментов, используя только оценки R и F.
Итог
RFM - это метод сегментации клиентов, управляемый данными, который позволяет маркетологам принимать тактические решения. Это позволяет маркетологам быстро идентифицировать и сегментировать пользователей в однородные группы и ориентировать их на дифференцированные и персонализированные маркетинговые стратегии. Это, в свою очередь, улучшает взаимодействие с пользователем и удержание.




