- Целевые переменные и атрибуты
- Нейронные сети
- Шаг 1. Открываем структуру исходных данных.
- Шаг 2. Начало моделирования. Открываем модуль «Нейронные сети Statistica», выбираем метод анализа.
- Шаг 3. Выбираем переменные и задаем параметры анализа.
- Шаг 4. В следующем окне выбираем подвыборки для обучения сети.
- Основные принципы обучения и критерии остановки
В течение последнего десятилетия в нефтегазовой отрасли произошла компьютеризация таких процессов, как управление бурением, каротаж высокого разрешения, телеметрия, сбор разнообразных данных на этапе разведки и эксплуатации и многих других. В этом материале мы сосредоточимся на новых аналитических технологиях для нефтедобывающей промышленности.
Построение моделей коллективных данных позволяет изменить способы анализа, моделирования процессов и в целом способствует оптимизации в отрасли. Многие прорывы в поиске месторождений произошли за счет сочетания геологии, петрофизики и геофизики. Сегодня на каждой пробуренной скважине размещены измерительные приборы, которые производят видео, изображения и структурированные данные. Это огромные массивы информации, самой разнообразной, всевозможных типов и масштабов.
Современные технологии data mining и машинного обучения позволяют работать с большими объемами данных, измеренных в разных шкалах: непрерывной, порядковой, категориальной, с разной частотой дискретизации. Классические методы статистики, имеющей дело с фиксированными наборами данных (выборками), устаревают и должны быть дополнены новыми интеллектуальными технологиями, поскольку подлинная революция в технологии анализа данных уже произошла.
Инженерам, работающим в нефтедобывающей промышленности, data mining дает ответы на многие ключевые вопросы, например:
- в каком направлении следует бурить горизонтальную скважину, чтобы уменьшить риск осложнений;
- как определить набор параметров, оказывающих максимальное влияние на возникновение осложнений;
- какую технологию ВИР следует применять в тех или иных условиях;
- как выбрать смеси для цементирования;
- как выбрать адекватного поставщика и т.д.
Целевые переменные и атрибуты
Первым шагом в создании моделей data mining является определение целевых переменных (target variables) и факторов, влияющих на них. Целевая переменная в контексте машинного обучения — это переменная, которая описывает результат (цель) процесса. Например, 0 — нет осложнений, 1 — есть осложнения.
В анализе данных мы называем такую переменную откликом или зависимой переменной. В более общей ситуации имеется несколько значений целевой переменной, указывающих на тип осложнений. Например, 0 — нет осложнений, 1 — есть осложнение типа 1, 2 — есть осложнение типа 2 и т.д.
Актуальной технологической задачей является определение набора параметров, которые оказывают максимальное влияние на возникновение осложнения. Для того, чтобы осуществить отбор атрибутов – то есть определить признаки, имеющие наиболее тесные связи с целевой переменной — нужно задействовать практических работников, инженеров, технологов.
В качестве примера возьмем проект бурения. Разломы и трещины в породе приводят к потерям бурового раствора, тяжелый раствор может разорвать породу, слишком легкий раствор не позволяет подавлять газопроявление, а это приводит к выбросам. Вибрация колонны может повредить оборудование и привести к разрушениям. Поэтому в проекте бурения должны быть учтены многие факторы, включая тип колонны, требования по закачиванию, предыстория и параметры бурового станка, подбор инструмента, оборудования, параметры цементирования и т.д. Ключевым моментом является взаимодействие факторов: они не только действуют на целевую переменную, но и взаимодействуют между собой. Так какие именно переменные следует включить в модель data mining?
Хорошая новость состоит в том, что специалисты в предметной области – инженеры и технологи — могут легко освоить нейросетевой инструмент для решения практических задач.
Итак, обратимся к технологии нейронных сетей.
Нейронные сети
Покажем, как строятся нейронные сети в программе STATISTICA и убедимся, что делается это просто.
Весь анализ проводится в удобной диалоговом режиме, позволяя пользователю видеть основное направление исследования данных. Даже новичок в аналитике может сделать первые успешные шаги. В качестве примера будем прогнозировать наличие или отсутствие нефти по результатам спектрального анализа.
Шаг 1. Открываем структуру исходных данных.
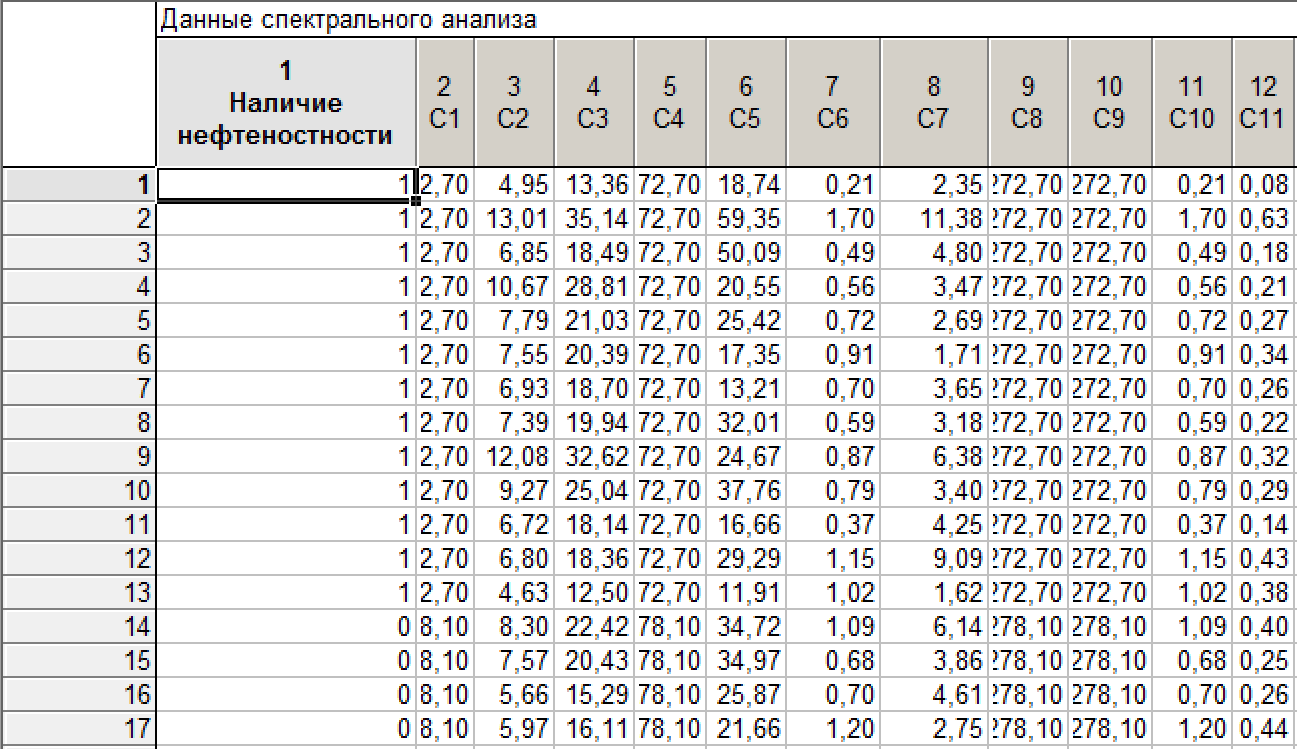
Рисунок 1. Предположим, структура выглядит следующим образом
Столбцы в таблице — это переменные, строки конкретные пробы. Целевой переменной является нефтеносность: наличие/отсутствие нефти (первая переменная). Также имеются переменные, описывающие параметры скважин.
Шаг 2. Начало моделирования. Открываем модуль «Нейронные сети Statistica», выбираем метод анализа.
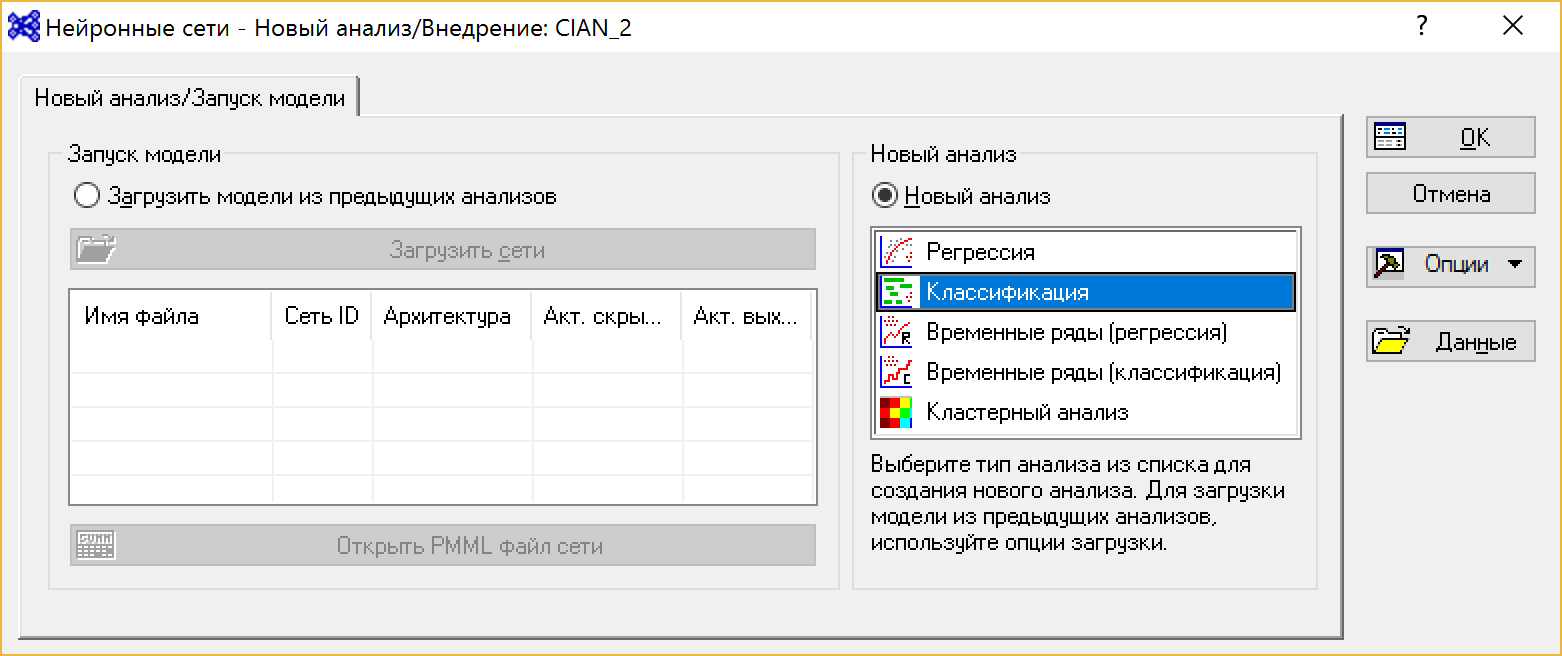
Рисунок 2. Стартовое окно нейронных сетей Statistica
Целевая переменная принимает два значения: 0 и 1, поэтому выбираем метод классификации в разделе Анализ, нажимаем ОК.
Шаг 3. Выбираем переменные и задаем параметры анализа.
Прежде всего указываем, какие переменные являются целевыми, какие факторы влияют на нее. Переменная нефтеносность является целевой, остальные переменные независимые или входные. Задача в том, чтобы оценить, как входные переменные влияют на целевую переменную.
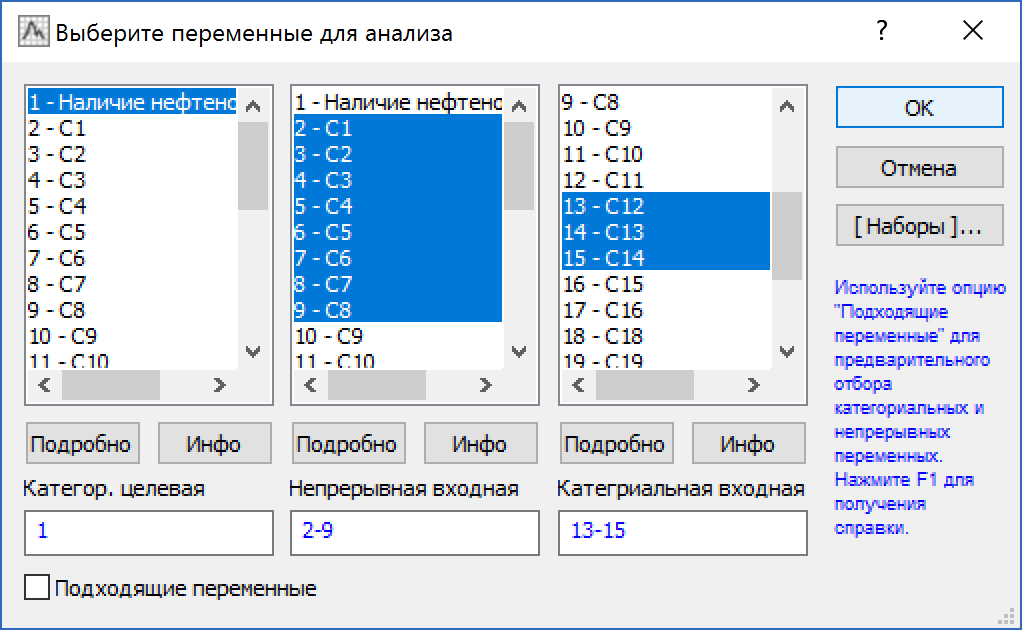
Рисунок 3. Окно выбора переменных
Шаг 4. В следующем окне выбираем подвыборки для обучения сети.
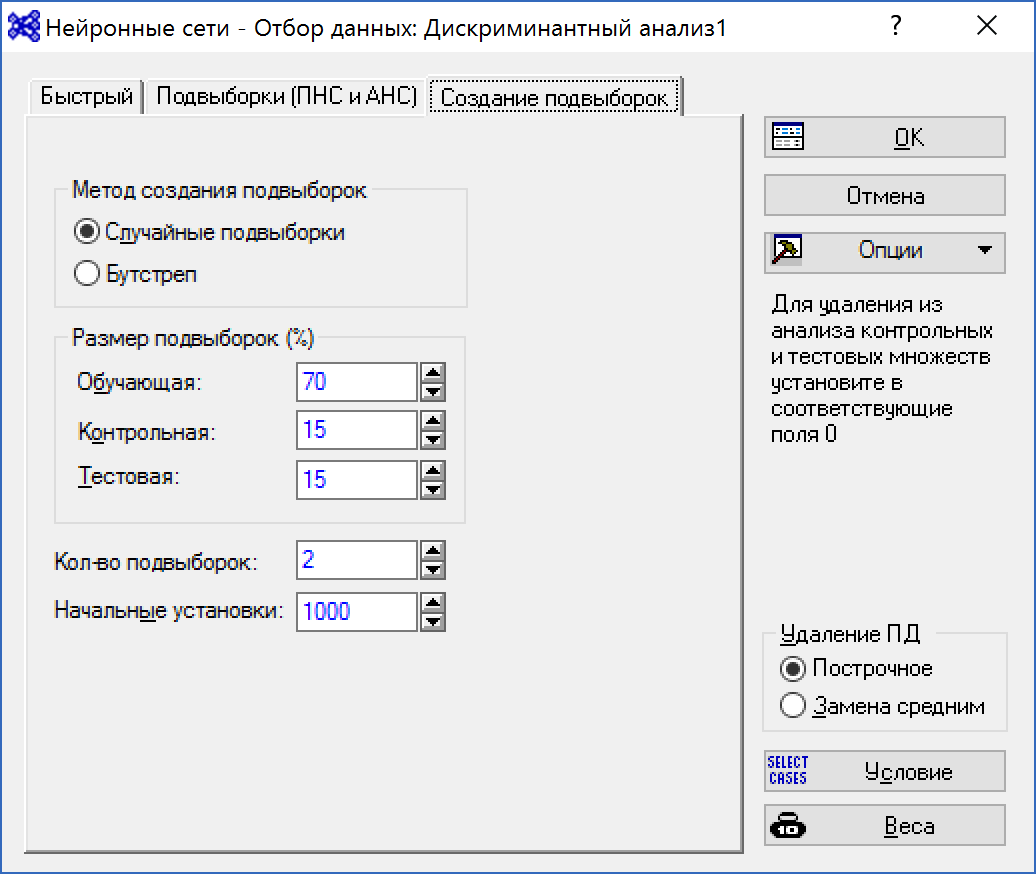
Рисунок 4. Задание подвыборок
Основные принципы обучения и критерии остановки
Это ключевой момент для понимания машинного обучения. Мы не можем обучать сеть до бесконечности, предъявляя все имеющиеся данные, сеть обучается до достижения минимума ошибок. Поэтому нужно разделить исходные данные на выборки: обучающую, контрольную, тестовую.
Отмечу, что эмпирически подход предполагает раннюю остановку процесса обучения сети, чтобы не допустить переобучения. Необходимо использовать набор валидаций для контроля точности обучения, это достигается с помощью контрольной выборки. Как только ошибка на выборке, контролирующей обучение, начинает возрастать, процесс обучения прекращается.
Тестовая выборка провидит проверку построенной и обученной сети, т.е. сети с найденными параметрами, на отдельном тестовом множестве.
Сеть обучается на выборке, составляющей обычно 70% наблюдений, процесс обучения контролируется на контрольной выборке (15% процентов наблюдений), построенная сеть проверяется на тестовой выборке (также 15% процентов наблюдений).
В отдельной вкладке можно выбрать тип сети, количество сетей для обучения и сохранения, функцию ошибок. Обычно используется сумма квадратов отклонений наблюдаемых и предсказанных значений, а также кросс-энтропия.
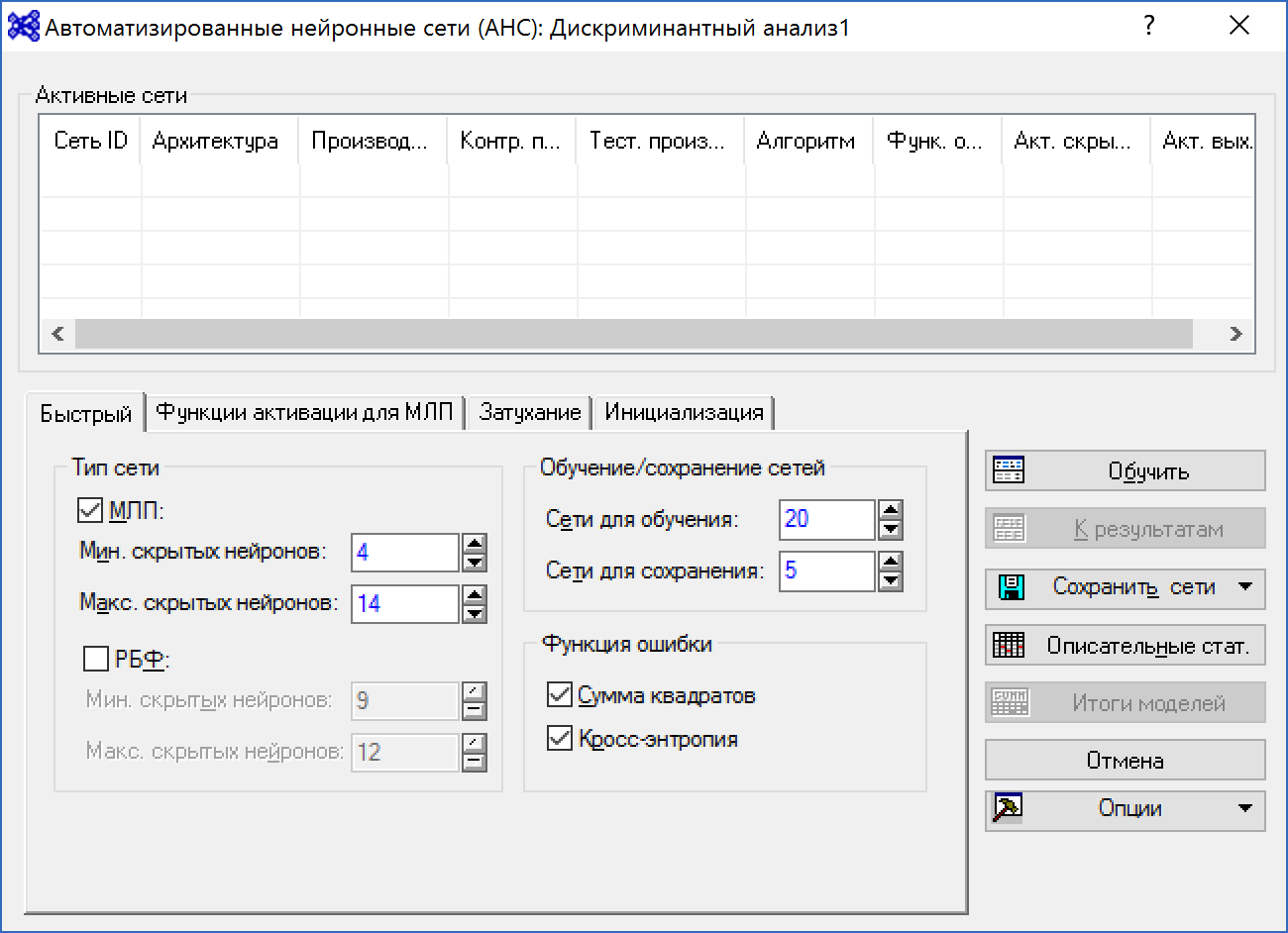
Рисунок 5. Окно спецификаций сетей
В этом диалоговом окне можно выбрать радиальные базисные функции и многослойные персептроны. Архитектура многослойных персептронов включает три вида нейронных слоёв: входной слой — NeuralInputs, скрытый слой — Hidden_NeuralLayer и выходной слой — NeuralOutputs.
Поток информации проходит от входных нейронов к выходным, формируя результат анализа.
В первых опытах с сетями рекомендуется использовать предопределенные настройки, которые впоследствии можно изменить, например, увеличить сложность сети, изменить число скрытых нейронов в многослойном персептроне, выбрать различные функции активации.
После того как основные параметры сети выбраны, запускаем процесс обучения.
Результаты определения нефтеносности на обучающей выборке показаны на рис. 6.
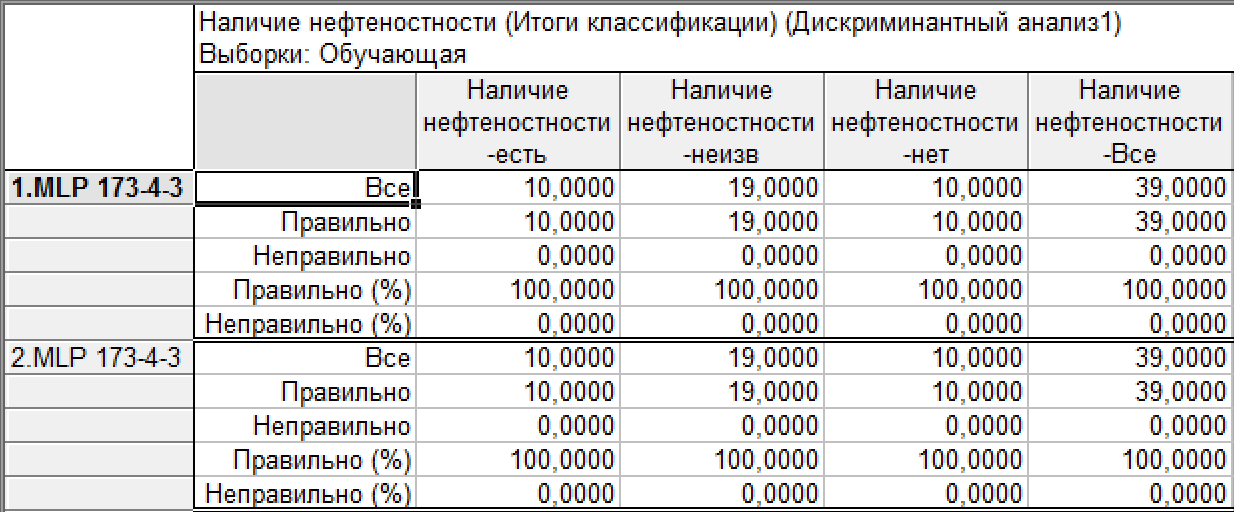
Рисунок 6. Результаты классификации
В этой таблице показана сеть MLP — многослойный персептрон, имеющий 173 входа и результаты сети на обучающей выборке.
Итак, сеть построена, вы оценили качество ее работы, теперь ее можно сохранить и использовать в деле!
Уверен, работа с нейронными сетями Statistica доставит вам удовольствие.
Углубленные и начальные курсы по анализу данных с помощью нейронных сетей также представлены в Академии Анализа Данных, пишите: academy@statsoft.ru
Автор: В. Боровиков, CEO StatSoft





