Содержание
- Alpha Zero
- Apache Hadoop
- Apache Spark
- JavaScript
- C-статистика
- CART
- ETL
- F-распределение Фишера
- Keras
- N факториал
- P-значение
- PageRank
- Pandas
- Python
- R2
- Statistica
- Structures Query Language (SQL)
- t-распределение
- TensorFlow™
- Абсолютное значение
- Алгоритм
- Алгоритм градиентного бустинга
- Алгоритм обратного распространения ошибки
- Альтернативная гипотеза, альтернатива
- Апостериорная вероятность
- Апостериорные сравнения
- Априорная, доопытная вероятность
- Арифметическое среднее
- Асимметричное распределение
- База данных | Database
- Базы данных XML
- Байесовский метод вывода
- Байесовская сеть
- Бернулли испытание
- Бета-уровень
- Бизнес-аналитика | Business Intelligence
- Бимодальное распределение
- Бинарная переменная
- Бинарные данные
- Биномиальная теорема
- Биномиальное распределение
- Блок, группа
- Большие данные | Big Data
- Большой объём данных | Big Data Volume
- Бонферрони поправка
- Бустинг
- Бутстреп
- Вариация остатков
- Вероятностные модели.
- Вероятность события
- Вероятность условная
- Взвешенное среднее
- Взвешенное среднее арифметическое | Weighted Average
- Воспроизводимость
- Временной ряд
- Вторая конечная точка
- Выбор модели
- Выборка | Sample, set
- Выборка обучающая | Training sample
- Выборка тестовая или контрольная | Test sample
- Выборка проверочная | Validation sample
- Выброс, аномальное значение
- Генератор случайных чисел
- Геометрическое распределение
- Гистограмма
- Градиент
- Антиградиент
- Группа контроля, группа сравнения
- Данные структурированные
- Данные неструктурированные
- Двухвыборочный критерий Вилкоксона ранговых сумм
- Дерево решений
- Детерминированный эксперимент
- Децили
- Диаграмма «стебель-листья»
- Диаграмма Венна
- Диаграмма рассеяния
- Дискретная переменная
- Дисперсионный анализ | ANOVA
- Дисперсия
- Доверительные границы
- Доверительный интервал для параметра
- Доверительный интервал
- Достоверность больших данных | Big Data Veracity
- Древовидная диаграмма
- Зависимая переменная
- Зависимые события
- Интеллектуальный анализ данных или дейта майнинг | Data Mining
- Интерквартильный размах
- Интернет вещей | Internet of Things (IoT).
- Интерполяция
- Каппа Кохена
- Категориальные данные
- Квартили
- Кластеры данных
- Кластерный анализ
- Клетка таблицы сопряжённости
- Коллинеарность
- Контрольная группа
- Конфаундинг | Confounding variable
- Корреляция
- Коэффициент детерминации
- Коэффициент корреляции Пирсона
- Коэффициент логистической регрессии
- Коэффициент ранговой корреляции Спирмена
- Корреляция Кендалла
- Кривая операционной характеристики
- Критерий Краскела
- Критерий Мак-Немара
- Критерий отношения дисперсий
- Критерий хи-квадрат Пирсона
- Критическая область | Critical region
- Круговой график
- Кумулятивная частота
- Линейный график
- Линия регрессии
- Лог-нормальное распределение
- Логистическая регрессия, логит-регрессия
- Лог-ранговый критерий
- Ложноотрицательный
- Ложноположительный
- Машинное обучение | Machine Learning
- Медиана
- Межквартильный размах
- Метаанализ
- Метод наименьших квадратов (МНК)
- Минимальное значение
- Множество
- Множественная линейная регрессия
- Мода
- Модель математическая
- Модель вероятностная
- Мощность критерия
- Независимая переменная
- Независимое событие
- Непараметрический критерий
- Непарный двухвыборочный
- Непересекающиеся множества
- Несмещенная оценка
- Номинальная переменная
- Номинальные данные
- Номограмма Альтмана
- Нормальное распределение
- Облачные вычисления | Cloud Computing
- Обобщенные линейные модели | GLM
- Объединение множеств
- Односторонний критерий
- Однофакторный дисперсионный анализ
- Описательная аналитика | Descriptive Analytics
- Остатки
- Остаточная дисперсия
- Относительная частота
- Относительный риск
- Отношение шансов
- Отрицательное предсказанное значение
- Первичная конечная точка
- Перекрёстные исследования
- Пересечение множеств
- Персептрон
- Подмножество
- Полиномиальная регрессия
- Предсказанное значение
- Предпроцессинг
- Прогностическая или предиктивная аналитика | Predictive Analytics
- Прогностическая ценность положительного результата
- Пуассоновская регрессия
- Радиальные базисные функции (РБФ)
- Размах
- Размер
- Разнообразие Больших Данных | Big Data Variety
- Ранговый коэффициент корреляции Спирмэна
- Рандомизация
- Регрессионная модель пропорционального риска Кокса
- Репозиторий
- Ретроспективное исследование
- Сезонная вариация
- Сериальная корреляция
- Систематический метод выборки
- Систематический обзор
- Систематическое размещение
- Скорость больших данных | Big Data Velocity
- Событие
- Софтмакс | Softmax
- Специфичность теста
- Среднее
- Среднее арифметическое
- Стандартное отклонение
- Статистический вывод
- Статистический критерий Вальда
- Стационарный временной ряд
- Столбчатая диаграмма
- Страта
- Оценка точечная
- Оценка интервальная
- Тренд
- Треугольник Паскаля
- Уровень доверия
- Уровень значимости
- Условная вероятность
- Фактор риска
- Факторный эксперимент
- Форест-график
- Формула Байеса
- Формула полной вероятности
- Функции активации в нейронных сетях
- Хи-квадрат критерий:
- Хранилище данных | Data Warehouse
- Цензурированные (неполные) данные
- Центральная предельная теорема
- Чувствительность
- Эмпирическое распределение
- Энтропия | Entropy
- Ящик с усами
Alpha Zero
Альфа зиро (Alpha Zero) - алгоритм игры в шахматы, основанный на нейронных сетях и самообучении.
Apache Hadoop
Apache Hadoop - платформа с открытым исходным кодом для обработки большого объема данных в кластерной среде. Он использует простую модель программирования MapReduce для надежных, масштабируемых и распределенных вычислений. Хранилище и вычисления распределены в этой структуре. Apache Hadoop обеспечила революцию больших данных, по крайней мере, с точки зрения программного обеспечения.
![]()
Apache Spark
Apache Spark - мощный движок обработки исходного кода, основанный на скорости, простоте использования и сложной аналитике с API-интерфейсами в Java, Scala, Python, R и SQL. Spark запускает программы до 100 раз быстрее, чем Apache Hadoop MapReduce в памяти, или в 10 раз быстрее на диске. Может использоваться для создания приложений данных в виде библиотеки или для интерактивного анализа данных ad hoc.
Spark предоставляет стек библиотек, включая SQL, DataFrames и Datasets, MLlib для машинного обучения, GraphX для обработки графов и Spark Streaming. Вы можете объединить эти библиотеки в одном приложении. Кроме того, Spark работает на ноутбуке, Apache Hadoop, Apache Mesos, автономно или в облаке. Он может обращаться к различным источникам данных, включая HDFS, Apache Cassandra, Apache HBase и S3.

JavaScript
JavaScript - язык сценариев (не имеющий отношения к Java), первоначально разработанный в середине 1990-х годов для встраивания логики в веб-страницы, но впоследствии зарекомендовал себя как универсальный язык разработки. JavaScript по-прежнему очень популярен для встраивания логики в веб-страницы, так как доступно множество библиотек для улучшения работы и визуального представления этих страниц.
C-статистика
C-статистика - оценивает площадь под ROC-кривой и может использоваться для оценки качества и сравнения диагностических тестов.
CART
Classification and regression trees - деревья классификации и регрессии. Алгоритм Classification and Regression Tree разработан Leo Breiman, Jerry Friedman, Charles Stone и Richard Olshen. Алгоритм строит бинарные деревья, имеющие двух потомков в каждом узле дерева. На каждом шаге построения дерева правило, формируемое в узле, делит заданную обучающую выборку на две части – часть, в которой выполняется правило (левый потомок) и часть, в которой правило не выполняется (правый потомок). Для выбора оптимального правила разбиения используется функция оценки качества разбиения. Функция оценки качества разбиения основана на идее уменьшения неопределенности в узле. Дерево решений с непрерывными выходными значениями называется деревом регрессии, деревья классификации выводят конкретные категориальные значения. В дереве имеется один особый узел, известный как корневой. Это основа дерева, от которой можно перейти по дереву к любому узлу. Ключевым моментом является иерархия разбиений. В результате последовательности проверок организуется процесс разбиения данных на непересекающиеся подмножества. Каждый листовой узел соответствует небольшой, но исключительной (неповторяющейся) части исходного множества.
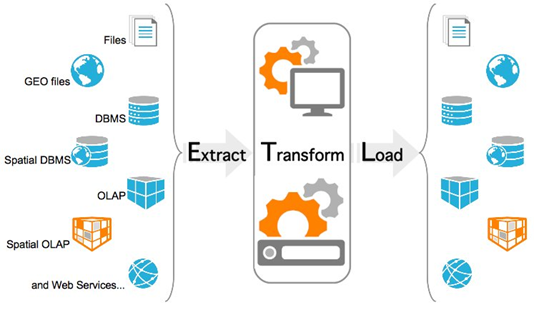
ETL
ETL (Extract, Transform, Load - Извлечение, Преобразование, Загрузка) - процесс извлечения данных из исходных систем, таких как транзакционные базы данных, и помещения их в хранилища данных. Если вы знакомы с онлайн-транзакционной обработкой (OLTP) и онлайн-аналитической обработкой (OLAP), ETL можно рассматривать как мост между этими двумя системными типами. Под ETL часто подразумевают как отдельную систему класса BI (или её компоненту), так и этап в анализе данных. Необходимость в ETL обусловлена разнообразием источников, в которых хранятся данные. Источники могут сильно отличаться как платформами, так и архитектурой: структура таблиц, разные справочники, различная детализация данных и др. Например, на производстве потоковые данные могут хранится в системе PI, а результаты прецизионных лабораторных замеров в системе LIMS. Причем разрешение данных в PI системе может быть доли секунды, а в LIMS – часы и даже сутки. Аналогично, может возникнуть задача компоновки данных из ERP, CRM, систем веб-аналитики и т.д. Этапы ETL процесса можно представить следующим образом:
- Загрузка данных из источников.
- Поиск, очистка/исправление ошибок в данных.
- Приведение к единим метрикам/размерностям/справочникам.
- Агрегация до необходимой детализации.
- Выгрузка в целевую систему/хранилище.
F-распределение Фишера
F-распределение Фишера - вытянутое вправо непрерывное распределение, характеризующееся степенями свободы числителя и знаменателя. Используется в дисперсионном анализе.
Keras
Keras - открытая нейросетевая библиотека, написанная на языке Python. Представляет собой надстройку над фреймворками Deeplearning4j, TensorFlow, Theano. Ключевая идея Keras: дать возможность переходить от идеи к результату в глубоком обучении с наименьшей возможной задержкой. Согласно исходной концепции Keras, является скорее интерфейсом, чем сквозной системой машинного обучения.
N факториал
N факториал - для положительного целого n, обозначение n! используется в таком виде:
n х (n-1) х (n-2) … х 2 х 1.
Например 5!=5х4х3х2х1=120.
0! определяется как 1.
P-значение
P-значение - вероятность получения наших результатов или чего-либо большего, если нулевая гипотеза верна; уровень значимости.
PageRank
PageRank - алгоритм, который определяет важность чего-либо, обычно ранжирует его в списке результатов поиска. PageRank работает путем подсчёта количества и качества ссылок на страницу, чтобы определить приблизительную оценку важности веб-сайта. Основное предположение заключается в том, что более важные веб-сайты могут получать больше ссылок с других веб-сайтов. PageRank назван не по названию страниц, которые он занимает, а по имени своего изобретателя, соучредителя и генерального директора Google Ларри Пейджа.
Pandas
Pandas - библиотека Python для манипулирования данными, популярная среди исследователей данных.
Python
Python - язык программирования, доступный с 1994 года, популярный среди исследователей, занимающихся наукой о данных. Python отличается простотой использования среди новичков и большой мощностью при использовании опытными пользователями, особенно когда используются преимущества специализированных библиотек, таких как библиотеки, предназначенные для машинного обучения и генерации графиков.
R2
R2 - коэффициент детерминации, доля общей дисперсии зависимой переменной в регрессионном анализе, которая объясняется моделью.
Statistica
Statistica - универсальная система анализа данных и дейта сайнс, содержащая как классические, так и современные методы анализа данных, доступные пользователям в удобном диалоговом режиме.
Statistica содержит более 10 000 аналитических и статистических процедур, включая машинное обучение и нейронные сети, и имеет более миллиона пользователей во всем мире. Коннектор Statistica с R позволяет эффективно использовать библиотеки открытого программного обеспечения.
![]()
Structures Query Language (SQL)
SQL - язык программирования, разработанный для управления и извлечения данных из системы реляционных баз данных.
t-распределение
Также называется распределением Стьюдента. Непрерывное распределение, чья форма подобна нормальному распределению и которое характеризуется своей степенью свободы. Используется для проверки гипотез о средних значениях выборки.
TensorFlow™
TensorFlow™ - программная библиотека с открытым исходным кодом для высокопроизводительных численных расчетов. Гибкая архитектура позволяет развертывать вычисления на различных платформах (процессорах, графических процессорах, TPU), от настольных компьютеров до кластеров серверов, мобильных и периферийных устройств. Обеспечивает поддержку машинного обучения и глубокого обучения, гибкое ядро для численных вычислений используется во многих других научных областях.
Абсолютное значение
Абсолютное значение - неотрицательное число, обозначаемое |x| и определяемое как:
если x < 0, то |x| = -x,
если x ≥ 0, то |x| = x.
Алгоритм
Алгоритм - упорядоченный набор действий (операций, процедур), которые приводят к достижению заранее поставленной цели. Например, алгоритм Евклида указывает, как найти наибольший общий делитель (НОД) двух натуральных чисел a и b.
Пусть a > b.
Шаг 1. a = b*q1 + r1
Если r1 = 0, то НОД (a, b) = b
Если r1 > 1, то шаг 2.
Шаг 2. b = r1*q2 + r2
Если r2 = 0, то НОД (a, b) = r1
Если r2 > 0, то шаг 3 и тд.
Так как b > r1 > r2 >…, то процесс заканчивается при любых заданных a и b за конечное число шагов и наибольший общий делитель будет найден.
Пусть требуется решить систему двух уравнений первой степени с двумя неизвестными x, y:
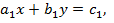
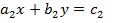
Алгоритм решения этой системы дается формулами
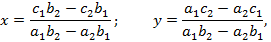
в которых полностью выражен как состав действий, так и порядок их выполнения.
В приведенных формулах предусмотрена одна и та же цепочка действий для всех задач данного типа. Алгоритм работает при любых коэффициентах 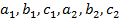 в предположении, что знаменатели приведенных выражений не обращаются в 0.
в предположении, что знаменатели приведенных выражений не обращаются в 0.
В противоположность классическому алгоритму, эвристические алгоритмы алгоритмы решения задачи, правильность которых не доказана для всех случаев, но про которые известно, что они дают достаточно хорошее решение в большинстве случаев. В дейта сайнс интенсивно используются разнообразные алгоритмы, в частности алгоритм градиентного спуска нахождения локального минимума функции потерь с помощью движения вдоль градиента.

Алгоритм градиентного бустинга
Алгоритм градиентного бустинга(boosting — улучшение, xgboost) — процедура последовательного построения композиции алгоритмов машинного обучения с целью улучшения качества классификации или предсказательной силы модели.
Алгоритм обратного распространения ошибки
Алгоритм обратного распространения ошибки(backpropagation) - применяется для обучения многослойных персептронов. Ключевая идея состоит в том, чтобы вычислить градиент функции потерь, необходимый для корректировки весов, которые необходимо использовать в сети. Вначале веса нейронов выбираются случайным образом, далее сеть обучается на входных наборах обучающей выборки. Выход нейрона зависит от взвешенной суммы его входов, который далее через передаточную функцию передается на другие нейроны и достигает последнего слоя. Функция потерь зависит от параметров сети и интуитивно представляет собой некоторую «стоимость», связанную с этими значениями. Фактически функция потерь задает меру несоответствия между ожидаемым сигналом на выходе сети и значением, которое наблюдается на обучающей выборки. Вначале ошибка вычисляется на последнем выходном слое, далее она подается на нейроны предыдущего слоя и тд. Корректировка весов производится с помощью метода градиентного спуска. Обычно функция потерь является квадратичной, функции активации нейронов дифференцируемые функции, что позволяет применять градиентный спуск.
Альтернативная гипотеза, альтернатива
Альтернативная гипотеза, альтернатива - гипотеза относительно интересующего нас эффекта, которая противоречит нулевой гипотезе и верна, если нулевая гипотеза ложная.
Апостериорная вероятность
Апостериорная вероятность - индивидуальное доверие, основанное на априорной вероятности и новой информации (например, результат критериальной проверки), в то, что событие произойдёт.
Апостериорные сравнения
Апостериорные сравнения - делаются для корректировки значения P, когда проводятся множественные (многократные) сравнения гипотез, например поправка Бонферрони или более мощная современная поправка Холма (1979).
Априорная, доопытная вероятность
Априорная, доопытная вероятность - априорная вероятность, оценённая до появления результата диагностического теста.
Арифметическое среднее
Арифметическое среднее - мера положения, полученная делением суммы значений переменной по наблюдениям на число слагаемых, часто называемая просто средним.
Асимметричное распределение
Асимметричное распределение - асимметричное распределение данных имеет длинный хвост справа с несколькими высокими значениями (положительно скошенное) или длинный хвост слева с несколькими низкими значениями (отрицательно скошенное).
База данных | Database
Для данных необходим особый способ хранения и обработки, чтобы они могли трансформироваться в информацию и далее использоваться для каких-либо полезных выводов. Базы данных обычно содержат совокупности записей данных или файлов, таких как последовательность производственных действий, транзакции, каталоги продуктов, запасы, профили клиентов и т.д. Данные обновляются, расширяются и удаляются по мере добавления новой информации. Данные организованы в строки, столбцы, таблицы, которые индексируются, чтобы упростить поиск необходимой информации. Одна из задач специалиста в дейта сайнс - уметь работать с системами управления базами данных, выгружать данные из различных баз данных для дальнейшего их анализа.

Базы данных XML
Базы данных XML позволяют хранить данные в формате XML. Базы данных XML часто связаны с документно-ориентированными базами данных. Данные, хранящиеся в базе данных XML, можно запрашивать, экспортировать в любой необходимый формат.
Байесовский метод вывода
Байесовский метод вывода - вывод на основе теоремы Байеса, использует не только текущую информацию, но и прежнее суждение о гипотезе для оценки апостериорной вероятности, оценивающей уровень доверия к гипотезе после наблюдаемых событий.
Байесовская сеть
Байесовская сеть - это вероятностная графическая модель (тип статистической модели), которая представляет набор переменных и их условных зависимостей с помощью направленного ациклического графа. Например, байесовская сеть может представлять вероятностные отношения между признаками клиента и его покупками. С учетом различных признаков сеть можно использовать для расчета вероятности приобретения тех или иных групп товаров, отклика на рекламу и т. д. Эффективные алгоритмы могут выполнять вывод и обучение в байесовских сетях. Байесовские сети, моделирующие последовательности переменных (например, речевые сигналы или белковые последовательности), называются динамическими байесовскими сетями. Обобщения байесовских сетей, которые могут представлять и решать задачи решения в условиях неопределенности, называются диаграммами влияния, основаны на теореме Байеса.
Бернулли испытание
Бернулли испытание - эксперимент только с двумя возможными исходами, например, выпадение герба или решки при бросании монеты. Вероятность выпадения герба полагается равной p, вероятность выпадения решки q.
0 < p, q < 1, p + q = 1.
Для симметричной монеты имеем следующие значения параметров распределения Бернулли: p = q = ½.
Случайная величина, равная числу успехов в N независимых испытаниях Бернулли, имеет биномиальное распределение, которое интенсивно используется в различных областях, включая телекоммуникации, страхование, промышленность (карты контроля качества).
Бета-уровень
(β-уровень) - вероятность ошибочного принятия нулевой гипотезы, когда в действительности верна альтернатива. В клинических исследованиях значение β-уровня обычно устанавливается равным 0,2 или 0,1. Величина (1- β) – статистическая мощность теста, в клинических исследованиях обычно 0,8 вероятность выявления разницы между группами при условии, что она действительно существует. Если выборки малы, то статистическая мощность может быть низкой. Для больших выборок статистические тесты имеют большую статистическую мощность, это означает, что истинные различия между группами выявляются с большей вероятностью.
Бизнес-аналитика | Business Intelligence
Бизнес-аналитика включает в себя стратегии, технологии и информационные системы, стремясь улучшить принятие решений на основе прошлых результатов с использованием отчетов, OLAP, панелей мониторинга, систем показателей, таблиц, визуализация данных, предиктивных моделей, построенных как с помощью классических статистических методов, так и с помощью дейта майнинга и машинного обучения.

Бимодальное распределение
Бимодальное распределение - распределение, имеющее две моды, два максимума плотности распределения. Обычно свидетельствует о неоднородности данных.
Бинарная переменная
Бинарная переменная - качественная переменная с двумя категориями, также называется дихотомической переменной.
Бинарные данные
Бинарные данные - данные, выражаемые только двумя альтернативными значениями, например, да, нет, при ответе респондентов.
Биномиальная теорема
Биномиальная теорема - даёт разложение (x + y)n, где n - любое натуральное число в виде:
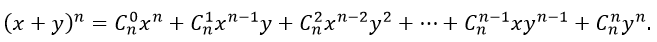
где 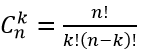 число сочетаний из n по k.
число сочетаний из n по k.
Например, (x + y)2 = x2 + 2xy + y2
(x + y)3 = x3 + 3x2y + 3xy2 + y3
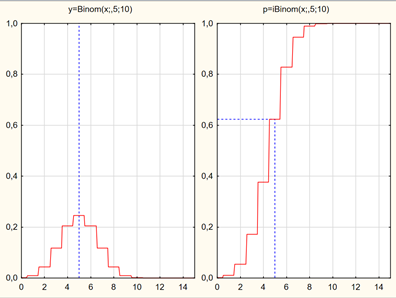
Биномиальное распределение
Биномиальное распределение - распределение количества «успехов» в последовательности из n независимых случайных экспериментов, таких что вероятность «успеха» в каждом из них равна p.
Рассмотрим независимые случайные величины 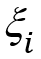 , имеющие распределение Бернулли: , принимает значение 1 или "успех" с вероятностью p; значение 0 или "неудача" с вероятностью q = 1 - p. Вероятность получить k успехов в серии n независимых испытаний равна:
, имеющие распределение Бернулли: , принимает значение 1 или "успех" с вероятностью p; значение 0 или "неудача" с вероятностью q = 1 - p. Вероятность получить k успехов в серии n независимых испытаний равна:
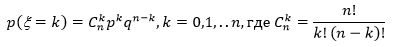
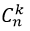 - число сочетаний из n по k;
- число сочетаний из n по k;
p - вероятность успеха в каждом испытании;
q - величина, равная 1-p;
n - число независимых испытаний.
Пример: вероятность выпадения двух гербов при двукратном бросании симметричной монеты равна ¼. Для симметричной (правильной) монеты выпадения герба или решки равновероятно: q = p = ½ 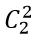 = 1, следовательно, вероятность выпадения двух гербов P (
= 1, следовательно, вероятность выпадения двух гербов P (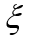 =2) =¼.
=2) =¼.
Блок, группа
Блок, группа - однородная группа экспериментальных единиц, которые имеют подобные характеристики, также называется «страта».
Большие данные | Big Data
Большие данные | Big Data - включает в себя стратегии, технологии и информационные системы, направленные на получение, обработку, хранение, анализ и визуализацию сложных структурированных и неструктурированных наборов данных с помощью пакетной обработки, потоковой обработки, NoSQL, HPC, MPP, In-Memory и других.

Большой объём данных | Big Data Volume
Объём относится к количеству сгенерированных и сохраненных данных. Размер данных определяет ценность и потенциальное понимание, и действительно ли это можно считать большими данными или нет.
Бонферрони поправка
Бонферрони поправка - поправка к уровню значимости, рассчитанному с помощью критерия парных сравнений, например, t-критерия, в случае, если сравниваются k > 2 выборок и проверяется k гипотез. При увеличении числа проверяемых гипотез мощность статистической процедуры резко уменьшается. Метод Холма равномерно более мощный, чем поправка Бонферрони в множественных (многократных) сравнениях, и решает проблему уменьшения мощности при увеличении числа проверяемых гипотез.
Бустинг
(boosting — улучшение) - процедура последовательного построения композиции алгоритмов машинного обучения с целью улучшения, например, качества классификации. При использовании комбинированного алгоритма качество классификации может быть увеличено.
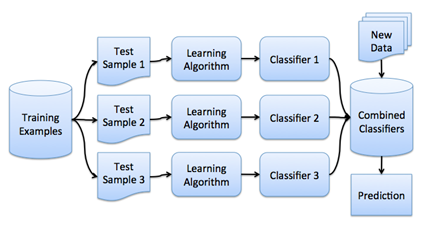
Бутстреп
Бутстреп - процесс моделирования, используемый обычно при получении оценок доверительного интервала для параметра. Использует для оценки параметра многократное извлечение случайных выборок, полученных из первоначальной выборки; после получения доверительного интервала рассматривается вариабельность распределения этих оценок.
Вариация остатков
Вариация остатков - вариация переменной, которая остаётся после того, как удалена вариабельность, относящаяся к интересующим нас факторам. Это вариация, не объяснимая моделью, также называется «ошибочная, или необъяснённая, вариация».
Вероятностные модели
Вероятностная модель представляет собой математическое представление случайного события. Он определяется пространством элементарных событий и вероятностью событий.
Вероятность события
Вероятность события - вероятность события А, обозначаемая P{A}, есть число, лежащее в диапазоне от нуля до единицы, указывающее, насколько правдоподобно данное событие. Вероятности событий подчиняются следующим правилам:
- P {A} = 1, если событие A наверняка произойдет (достоверное событие);
- P {A} = 0, если событие A невозможно (не может осуществиться);
- P {AꓴB} = P{A}+P{B} - P{A∩B}
- Если события A и B не могут осуществиться одновременно (являются несовместными), то: P {AꓴB} = P{A}+P{B}
- P {не A} = 1-P{A}
Вероятность условная
Вероятность условная - вероятность наступления события А при условии, что наступило событие В: P {A|B} = P{A∩B}/P(B), P(B) > 0.
Взвешенное среднее
Взвешенное среднее - модификация среднего арифметического, полученная путём учёта веса по каждому значению переменной в группе данных.
Взвешенное среднее арифметическое | Weighted Average
Взвешенное среднее арифметическое | Weighted Average - метод вычисления среднего арифметического набора чисел, в котором одни элементы множества имеют большее значение (вес), чем другие.
Воспроизводимость
Воспроизводимость - степень совпадения экспериментальных значений, полученные в идентичных условиях.
Временной ряд
Временной ряд - значение переменной, наблюдаемые в последовательных точках во времени.
Вторая конечная точка
Вторая конечная точка - исходы в клиническом исследовании, которые не имеют главного значения.
Выбор модели
Выбор модели - процедура формирования упрощённой схемы изучаемого явления. В регрессионном анализе выбор модели может проводиться с использованием разных алгоритмов отбора предикторов в уравнении регрессии. Наиболее популярны модели пошагового включения и исключения предикторов, а также их комбинации.
Выборка | Sample, set
Выборка | sample, set - конечный набор данных из генеральной совокупности, который получается с помощью определенного процесса, возможно случайного выбора или отбора на основе определенных критериев для расследования свойств основной исходной совокупности.
Выборка обучающая | Training sample
Выборка, на которой производится обучение алгоритма, в частности, нейронной сети с целью минимизации заданной функции потерь.
Выборка тестовая или контрольная | Test sample
Выборка тестовая или контрольная - выборка, на которой оценивается качество построенной модели и контролируется процесс обучения с целью исключения эффекта переобучения. Тестовый набор данных не зависит от обучающей выборки, но имеет одинаковое с ней распределение вероятностей.
Выборка проверочная | Validation sample
Выборка, на которой осуществляется проверка модели из множества моделей, построенных по обучающей выборке и выбирается лучшая модель.
Выброс, аномальное значение
Выброс, аномальное значение - наблюдение, которое отличается от основной части данных и несовместимо с остальными данными. Выбросы смещают оценки и устраняется на этапе предварительной обработки (чистки) данных.
Генератор случайных чисел
Генератор случайных чисел - программа, которая позволяет генерировать псевдослучайные числа.
Геометрическое распределение
Геометрическое распределение - дискретное распределение вероятности числа испытаний, необходимых для достижения первого успеха в последовательности испытаний Бернулли. Вероятность того, что первый успех произойдет на шаге k равна Pk = p (1 - p)k-1. Например, вероятность того, что при бросании симметричной монеты герб первый раз выпадет на шаге 3 равна:
P3 = 0,5 (0,5)2 = 0,125
Вероятность того, что при бросании симметричной монеты герб первый раз выпадет на шаге 5 равна:
P5 = 0,5 (0,5)4 = 0,03125
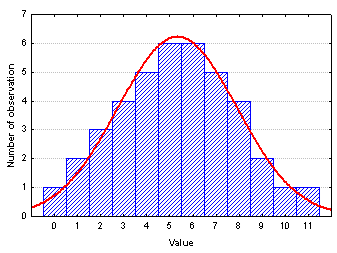
Гистограмма
Гистограмма - диаграмма, представляющая распределение частот значений переменной (или частот значений на каждом из интервалов, на которые разбита выбранная область изменения переменной). Огибающая гистограммы показывает форму функции плотности распределения.
Градиент
Градиент скалярной функции f(x1, … xk) определяется как вектор ее частных производных:
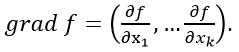
Для обозначения градиента используется также оператор набла: 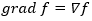
Градиент указывает направление наибольшего возрастания функции и перпендикулярен линии уровня в данной точке. Модуль градиента показывает максимальную скорость изменения функции в окрестности точки или частоту линий уровня.
Антиградиент
Антиградиент - вектор, противоположный градиенту, т.е. это вектор, компоненты которого по абсолютной величине совпадают с компонентами градиента, но имеют противоположный знак. Антиградиент указывает направление наибольшего убывания функции. Формально антиградиент функции f(x1, … xk) равен - grad f. Пример: f(x,y) = x**2 + y**2, в точке (1,1) имеем: grad f (1,1) = (2, 2), antigrad (1,1) = (-2, -2).
Группа контроля, группа сравнения
Группа контроля - пациенты в рандомизированном контролируемом исследовании, которые не получают активного лечения.
Данные структурированные
Данные структурированные - данные, которые организованы по заранее определенной структуре.
Данные неструктурированные
Данные неструктурированные - данные, которые либо не имеет заранее определенной структуры, либо не организованы в определенном порядке, например, текстовые данные. Большие данные представляют собой совокупность структурированных и неструктурированных данных.
Двухвыборочный критерий Вилкоксона ранговых сумм
Двухвыборочный критерий Вилкоксона ранговых сумм - непараметрический критерий, сравнивающий распределение двух независимых групп наблюдений.
Дерево решений
Формально дерево решений - это древовидный граф, состоящий из узлов и листьев, соединённых между собой рёбрами. В узлах графа происходит принятие решений, а листья указывают на классы. Граф дерева решений должен быть ациклический, иначе он перестает быть древовидным. Деревья решений подразделяются на два типа: деревья классификации и деревья регрессии. Определяющим фактором, от которого зависит тип дерева, является выходное значение, непрерывное или категориальное.
Детерминированный эксперимент
Детерминированный эксперимент- процесс, в котором результат определен заранее.
Децили
ецили- величины, которые делят упорядоченные наблюдения на 10 равных частей (по числу наблюдений).
Диаграмма «стебель-листья»
Диаграмма «стебель-листья» - полуграфический метод, используемый для представления числовых данных, в котором первая (крайняя слева) цифра каждого значения данных является стеблем, а остальные цифры числа — это листья.

Диаграмма Венна
Диаграмма Венна - графические средства отображения пересечения и объединения множеств, представляя их как ограниченные области.
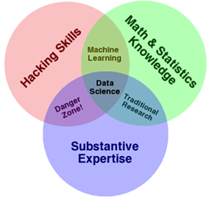
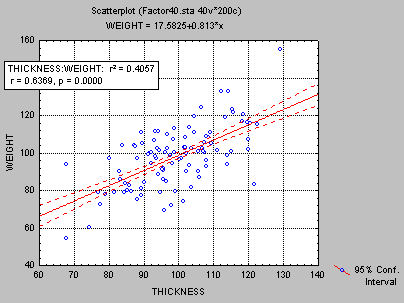
Диаграмма рассеяния
Диаграмма рассеяния - график двух переменных, в которых каждая точка определяется по ее координатам (X, Y). Например, высота и вес.
Дискретная переменная
Дискретная переменная - числовая переменная, которая может принимать дискретные значения.
Дисперсионный анализ | ANOVA
Дисперсионный анализ | ANOVA - общий термин для методов, которые сравнивают средние значения групп наблюдений путём расщепления общей дисперсии переменной на её компоненты, причём каждая относится к отдельному фактору. Дисперсионный анализ (ДА) представляет собой набор статистических моделей для анализа различий между групповыми средними и связанными с ними процедур (например, «вариации» в группе и между группами). В ДА наблюдаемое отклонение конкретной переменной разбивается на составляющие, относящихся к разным источникам вариации. В своей простейшей форме, ДА является статистическим тестом на равенство средних нескольких групп, и поэтому обобщает t-тест Стьюдента на случай трех и более групп. Многократное использование двухвыборочного t-теста приведет к увеличению вероятности ошибки первого рода. По этой причине ДА полезен при сравнении трех и более средних (групп и переменных) с точки зрения статистической значимости. Существует три класса моделей, которые используют в дисперсионном анализе:
- Модель с фиксированными эффектами
Данная модель используется тогда, когда экспериментатор применяет одно или несколько воздействий на объект исследования, чтобы понять, меняется ли зависимая переменная. Это позволяет экспериментатору оценить диапазон значений зависимых переменных, который бы наблюдался, если бы воздействие было направлено на всю популяцию.
- Модель со случайными эффектами
Данная модель используется тогда, когда воздействия не фиксированы. Это происходит тогда, когда различные уровни факторов является выборкой из большей популяции. Поскольку сами уровни являются случайными величинами, некоторые предположения и метод контрастирующего воздействия отличаются от модели с фиксированными эффектами.
- Модель со смешенными эффектами
Данная модель содержит экспериментальные факторы и фиксированного и случайного типа, с соответствующими различными интерпретациями и анализами двух типов.
Пример: Эксперимент состоит в том, что несколько дизайнеров разрабатывают упаковку продукта. При этом каждый вариант упаковки считается воздействием. Модель с фиксированными эффектами будет сравнивать вид упаковки. Модель со случайными эффектами могла бы определить, существуют ли важные различия между восприятиями случайно выбранных покупателей. Модель со смешенными эффектами будет сравнивать данную упаковку с несколькими случайно выбранными альтернативами.
Дисперсия
Дисперсия - способ описания рассеяния или вариабельности наблюдений в выборке. Общими мерами вариабельности данных являются дисперсия, стандартное отклонение, межквартильный размах.
Доверительные границы
Доверительные границы - верхняя и нижняя величины доверительного интервала.
Доверительный интервал для параметра
Доверительный интервал для параметра - диапазон значений, внутри которого, как мы (обычно) верим на 95%, лежит истинный параметр популяции. Строго говоря, после повторных отборов в этом интервале лежит 95% оценок этого параметра.
Доверительный интервал
Доверительный интервал - интервал, вычисленный из выборки, который содержит значение определенного параметра совокупности с определенной вероятностью.
Достоверность больших данных | Big Data Veracity
Достоверность - это качество данных, которое может сильно различаться, что влияет на точный анализ.
Древовидная диаграмма
Древовидная диаграмма - диаграмма, отображающая все возможные результаты события.
Зависимая переменная
Зависимая переменная - переменная (обычно обозначенная как Y), которая предсказана независимой переменной в регрессионном анализе, также называется откликом.
Зависимые события
Зависимые события - два события зависимы, если наступление одного влияет на вероятность наступления другого.
Интеллектуальный анализ данных или дейта майнинг | Data Mining
Обычно интеллектуальный анализ данных определяют как «применение определенных алгоритмов для извлечения шаблонов из данных». При интеллектуальном анализе данных акцент делается на применении алгоритмов, в отличие от самих алгоритмов. Мы не выдвигаем заранее гипотез относительно данных, а находим взаимосвязи в данных. Мы можем определить взаимосвязь между машинным обучением и интеллектуальным анализом данных следующим образом: интеллектуальный анализ данных - это процесс, в ходе которого алгоритмы машинного обучения используются в качестве инструментов для извлечения потенциально ценных шаблонов, хранящихся в наборах данных.

Интерквартильный размах
Интерквартильный размах - разница между первым и третьим квартилем (IQR).
Интернет вещей | Internet of Things (IoT).
Концепция IoT позволяет вести интернет-связь между физическими объектами, датчиками и контроллерами. Данные IoT поступают с устройств, которые часто записывают процессы с большим количеством помех (температура, давление, скорость), в результате данные этих устройств зачастую содержат ощутимые пробелы, поврежденные сообщения и ложные показания, которые необходимо очистить перед тем, как провести анализ и провести предобработку (предпроцессинг).
В металлургии прокатка стали может проводиться с разной скоростью, давлением, температурой, в нефтедобывающей промышленности в реальном времени проводится мониторинг состояния погружного насосного оборудования (УЭЦН). Технологии IoT позволяют вести мониторинг потребления электроэнергии на предприятии, состояния оборудования, онлайн-мониторинг вибрации позволяет предотвратить отказ оборудования, разрушение зубцов в редукторе, отказ подшипников, выявить проблемы со смазкой и т. д. Отслеживание пиков вибрации в реальном времени, так называемая технология пиковых нагрузок (Peak Value), позволяет минимизировать отказы насосов и сократить расходы на обслуживание. Данные о вибрации передаются в систему управления технологическими процессами, анализируются с помощью заранее настроенных и тестированных моделей. Интернет вещей - Internet of Things (IoT) - является растущим источником генерации больших данных. Внедрённая сеть позволяет технически быстро и эффективно получать информацию о состоянии объектов контроля, добавлять и переносить беспроводные приборы для получения дополнительной информации о процессах в удаленных или труднодоступных местах.

Интерполяция
Интерполяция - оценка неизвестного значения, которое лежит между двумя известными значениями.
Каппа Кохена
Каппа Кохена - мера согласия между двумя группами качественных измерений на одних субъектах.
Если ĸ=1 - совершенное согласие, если ĸ=0 - не лучше, чем случайное согласие.
Использование коэффициентов корреляции, таких как r Пирсона, может плохо отражать степень согласия между экспертами, что приводит к чрезмерному завышению или занижению истинного уровня согласия. Значения каппа ≤ 0 указывают на отсутствие согласия, 0,01–0,20 - на несущественное, 0,21–0,40 - на удовлетворительное, 0,41–0,60 - на умеренное, 0,61–0,80 - на значительное и 0,81–1,00 на почти полное, идеальное согласие.
Пусть два эксперта оценивают одни и те же объекты, например, качество товара или эффективность рекламной кампании. Проверяемая гипотеза: оценки экспертов являются независимыми. Альтернатива - между экспертами есть согласие. Гипотезу можно проверить с помощью статистики каппа Кохена (Cohen’s kappa). Формула для каппа Кохена имеет вид:
Каппа Кохена = k = 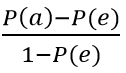
где P(a) вероятность наблюдаемого согласия экспертов, P(e) вероятность случайного согласия экспертов (в предположении, что действия экспертов независимы).
Для таблицы сопряженности 2 на 2, в случае, когда 2 эксперта при сравнении n объектов дают ответ да или нет, P(e) оценивается следующим образом:
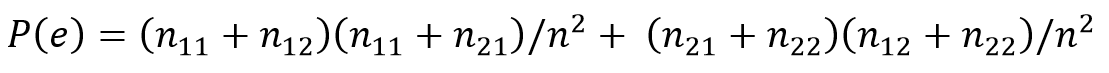
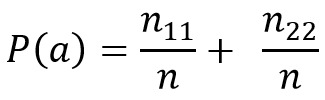
Пусть два эксперта оценивают 222 объекта, n = 222
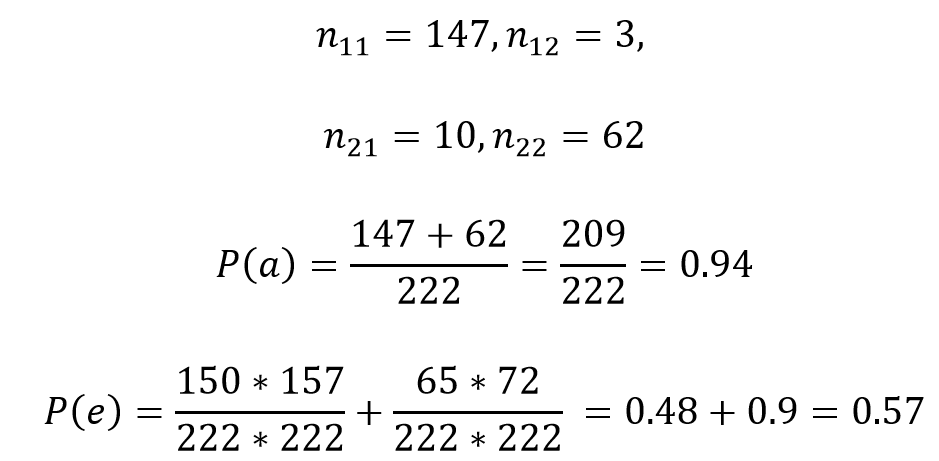
Тогда каппа Кохена = k = (0.94 – 0.57)/(1 - 0.57) = 0.86
95% доверительный интервал для каппа определяется как
(k − 1.96 × SEk , k + 1.96 × SEk)
где SEk стандартная ошибка оценки.
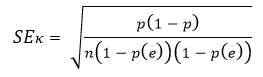
где p вероятность согласия, вычисленная как
p = (n11 + n22) / n
Обобщением каппа Кохена является статистика каппа Флейса (Fleiss kappa), применяемая для оценки согласия трех и более экспертов. Заметим, что каппа Кохена - это форма коэффициента корреляции. Коэффициенты корреляции не могут быть интерпретированы непосредственно, но квадрат коэффициента корреляции, называемый коэффициентом детерминации, интерпретируется и объясняет, какая доля вариации в зависимой переменной может быть объяснена независимой переменной. Возведение в квадрат значения каппа концептуально преобразуется в величину точности в данных, возникающую из-за согласия экспертов.
Категориальные данные
Категориальные данные - данные, которые описываются небольшим числом дискретных категорий, например, пол респондента, мужской или женский, является категориальной переменной.
Квартили
Квартили - значения, которые делят упорядоченные наблюдения на четыре равные части. Различают нижний, верхний квартиль, а также медиану выборки.
Кластеры данных
Кластеры данных - часть высокой концентрации групп данных в наборе данных, скопление однотипных объектов, которые близки между собой и отличаются от других объектов выборки.
Кластерный анализ
Кластерный анализ - метод машинного обучения без учителя, который включает группировку данных. Учитывая набор точек данных, мы можем использовать алгоритм кластеризации для классификации каждой точки в определенную группу или коастер. Теоретически, наблюдения, которые находятся в одной и той же группе, должны иметь схожие свойства, тогда как наблюдения в разных группах должны иметь очень разнородные свойства. Кластеризация - это метод неконтролируемого обучения и является общей методикой анализа статистических данных, используемой во многих областях.
В Data Science мы можем использовать метод кластеризации, чтобы получить ценную информацию из наших данных, видя, к каким группам они относятся, после применения алгоритма кластеризации. Популярные методы кластерного анализа: K-Means, MeanShift, DBSCAN, expectation maximization (EM) algorithm, иерархическая кластеризация.
Клетка таблицы сопряжённости
Клетка таблицы сопряжённости - пересечение отдельной строки и отдельного столбца таблицы сопряженности. Матрица ошибочной классификации алгоритма машинного обучения является типичным примером таблицы сопряженности, в которой на диагонали указано число правильно классифицированных объектов, вне диагонали число ошибочно классифицированных объектов.
Коллинеарность
Коллинеарность - пары независимых переменных в регрессионном анализе высоко коррелируют, если их корреляции по модулю близки к единице.
Контрольная группа
Контрольная группа - термин, применяемый в сравнительных исследованиях, например, в клинических испытаниях, для обозначения группы сравнения.
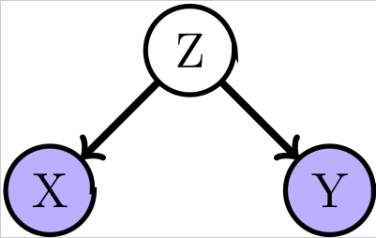
Конфаундинг | Confounding variable
Конфаундинг(также confounding variable, confounding factor,lurking variable). В анализе данных и дейта сайнс смешивающая переменная (смешивающий фактор) - переменная, которая влияет как на зависимую переменную, так и на независимую переменную, искажая результаты исследования.
Корреляция
Корреляция - корреляция между двумя переменными x и y является мерой связи между переменными. Корреляционный анализ исследует степень связи между переменными x и y, например, между числом посетителей интернет-магазина (хостов) и покупкой товаров, площадью квартиры и цена, объемом двигателя и стоимостью автомобиля и др.
Пусть имеем выборку (x1. y1), (x2, y2),…,(xn, yn)
Выборочный коэффициент корреляции Пирсона r формально определяется как
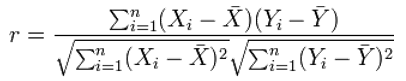
- Коэффициент корреляции изменяется в интервале от -1 до +1
- Если r>0, то говорят о положительной коррелированности величин
- Если r<0, то говорят об отрицательной коррелированности величин
- Если r = 0, то говорят о некоррелированности величин
- Чем ближе r к крайним точкам (±1), тем больше степень линейной связи
На практике используют следующее эмпирическое правило:
- r
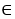 [-0.25 to +0.25] → нет связи
[-0.25 to +0.25] → нет связи - r (0.25 to +0.50] или (-0.25 to -0.50] → слабая связь
- r (0.50 to +0.75] или (-0.50 to -0.75] → умеренная связь
- r (0.75 to +1) или (-0.75 to -1) → сильная связь
Эквивалентное выражение дает коэффициент корреляции как среднее стандартных оценок. Основываясь на выборке из парных данных (Xi, Yi), выборочный коэффициент корреляции Пирсона определяется также как:
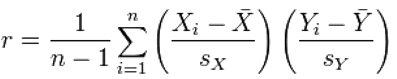
где
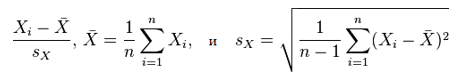
— это стандартизация, выборочное среднее и выборочное стандартное отклонение, соответственно. Мы можем отметить точку, соответствующую паре величин, на графике. Обычно на графике переменную x располагают на горизонтальной оси, а у — на вертикальной. Получаем график, так называемая диаграмма рассеяния, который говорит о соотношении между двумя переменными. Величина r показывает, как близко расположены точки к прямой линии. Ключевым математическим свойством коэффициента корреляции Пирсона является инвариантность (с точностью до знака) при сдвиге и масштабировании двух переменных. То есть, мы можем преобразовать переменную X в a + bX и переменную Y в c + dY, где a, b, c, и d – некоторые постоянные, не меняя коэффициент корреляции. На практике, доверительные интервалы и проверка гипотез, относящихся к ρ обычно осуществляется с использованием преобразования Фишера:
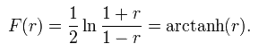
Бутстреп может быть использован для построения доверительных интервалов для коэффициента корреляции Пирсона.
Коэффициент вариации - стандартное отклонение, делённое на среднее, часто выражено в процентах, является мерой вариабельности данных.
Коэффициент детерминации
Квадрат коэффициента корреляции обозначается r2 и называется коэффициентом детерминации. Коэффициент детерминации оценивает долю изменчивости переменной Y, которая объясняется с помощью переменной X в линейной регрессионной модели. Пусть имеем пару переменных Х и Y, принимающих значения X1 ... Xn, Y1 ... Yn. Например, наблюдаем значения независимой переменной Xi и соответствующие значения отклика Yi, дозу лекарственного препарата и эффект, долю примеси и проводимость медной проволоки и т. д. Мы хотим понять, как переменные Х и Y связаны между собой. Одной из разумных мер зависимости является коэффициент корреляции. Формально выборочный коэффициент корреляции между переменными Х и Y имеет вид:
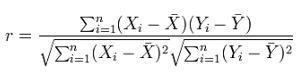
где 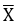 – среднее величины Х,
– среднее величины Х, 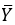 – среднее величины Y:
– среднее величины Y:
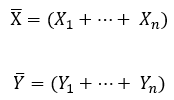
Так как коэффициент корреляции меняется в пределах от -1 до +1, то коэффициент детерминации лежит в пределах от 0 до +1. На первый взгляд громоздкая формула имеет простой смысл. Покажем, как коэффициент корреляции и коэффициент детерминации связаны с линейной регрессией. Пусть по наблюдениям Xi, Yi построена линейная регрессионная модель:
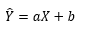
где коэффициенты a, b оценки по методу наименьших квадратов. Общее изменение Yi относительно среднего значения можно разложить по формуле:
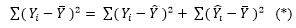
где 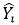 - предсказанные значения Y.
- предсказанные значения Y.
Это замечательное выражение называется основным тождеством регрессионного анализа.
Выражение (*) можно преобразовать:
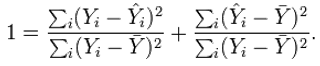
Затем мы применяем свойство наименьших квадратов регрессионной модели, заключающееся в том, что ковариация выборки между предсказанными значениями и остатками и Yi — равна нулю. Таким образом, коэффициент корреляции выборки между наблюдаемыми и предсказанными значениями равен:
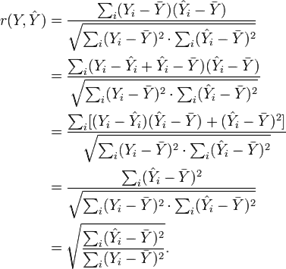
Отсюда получаем, что квадрат коэффициента корреляции или коэффициент детерминации равен доле дисперсии, которая объясняется в линейной регрессионной модели:
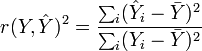
Коэффициент корреляции Пирсона
Пусть имеем выборку (x1. y1), (x2, y2),…,(xn, yn). Выборочный коэффициент корреляции Пирсона r формально определяется как
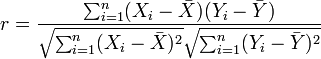
где 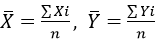
- Коэффициент корреляции лежит в интервале от -1 до +1
- Если r>0, то говорят о положительной коррелированности величин
- Если r<0, то говорят об отрицательной коррелированности величин
- Если r = 0, то говорят о некоррелированности величин
- Чем ближе r к крайним точкам (±1), тем больше степень линейной связи
На практике используют следующее эмпирическое правило оценки связи между двумя переменными:
- r [-0.25 to +0.25] → нет связи
- r (0.25 to +0.50] или (-0.25 to -0.50] → слабая связь
- r (0.50 to +0.75] или (-0.50 to -0.75] → умеренная связь
- r (0.75 to +1) или (-0.75 to -1) → сильная связь
Для пар с некоррелированным двумерным нормальным распределением, выборочное распределение коэффициента корреляции Пирсона соответствует t-распределению Стьюдента с степенями свободы n - 2. Доверительные интервалы и проверка гипотез относительно коэффициента корреляции Пирсона обычно проводится с использованием преобразования Фишера:
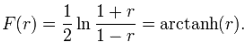
Для получения доверительного интервала для ρ, вначале вычислим доверительный интервал для F(ρ):
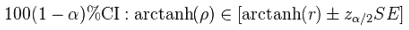
Далее используем обратное преобразование Фишера:
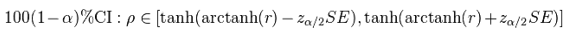
Коэффициент логистической регрессии
Коэффициент логистической регрессии- коэффициент регрессии для конкретного предиктора в логистической регрессии.
Коэффициент ранговой корреляции Спирмена
Коэффициент ранговой корреляции Спирмена - аналог коэффициента корреляции Пирсона, вычисленный по рангам наблюдаемых величин. Если заменить в формуле для коэффициента корреляции Пирсона наблюдаемые значения их рангами, то получим коэффициент корреляции Спирмена. Пусть имеется две выборки: X=(x1,x2,...,xn), Y=(y1, y2, ..., yn). Обозначим за Ri - ранг наблюдения xi, а Si - ранг наблюдения yi. Тогда коэффициент корреляции Спирмена вычисляется по формуле:
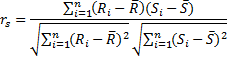
где 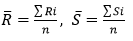
В случае несовпадающих рангов имеет место следующая формула для коэффициента ранговой корреляции Спирмена:
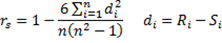
Коэффициент корреляции Спирмена r всегда лежит в интервале −1 ≤ r ≤ 1. Для проверки гипотезы об отсутствии корреляции можно использовать критерий перестановок или аналог преобразования Фишера. Один из подходов к проверке того, значительно ли выборочное значение корреляции Спирмена отличается от нуля заключается в применении теста перестановок. Преимущество подхода заключается в том, что автоматически учитывается число совпадающих значений в данных.
Корреляция Кендалла
Пусть наблюдаются значения (x1, y1), (x2, y2), …, (xn, yn) случайных величин X и Y такие, что все наблюдаемые значения различны. Тогда коэффициент ранговой корреляции Кендалла равен:
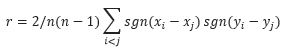
Если наблюдаемые величины являются независимыми, то среднее статистики r равно 0. Для малых выборок распределение ранговой корреляции Кендалла r можно вычислить точно, для больших выборок используют нормальное приближение. При больших n распределение коэффициента Кендалла приблизительно равно нормальному распределению со средним 0 и дисперсией 2(2n + 5)/9n(n-1).
Кривая операционной характеристики
Кривая операционной характеристики (ROC-кривая) - монотонная кривая, позволяющая оценить качество бинарной классификации. По оси Х откладывается вероятность ошибочной классификации объекта без признака (false positive rate), по оси Y вероятность истинной классификации объекта с признаком (true positive rate). Применяется для сравнения тестов и выбора оптимального порога классификации. Ключевым показателям является AUC (area under curve), площадь под ROC-кривой. Чем выше показатель AUC, тем качественнее работает алгоритм классификации.
Критерий Краскела
Критерий Краскела-Уоллиса - непараметрическая альтернатива однофакторного дисперсионного анализу ANOVA. Применяется для сравнения распределений более двух независимых групп наблюдений.
Критерий Мак-Немара
Критерий Мак-Немара - сравнивает доли (пропорции) в двух соотносящихся группах, применяя статистику критерия хи-квадрат Пирсона.
Критерий отношения дисперсий
Критерий отношения дисперсий - F-критерий Фишера-Снедекора, используется для проверки гипотез о равенстве дисперсий в популяции.
Критерий хи-квадрат Пирсона
Критерий хи-квадрат Пирсона: используется в частотных данных. Он проверяет нулевую гипотезу, что нет связи между факторами, которые определяют таблицу сопряженности. Также применяется для тестирования разницы в долях (пропорциях) данных.
Критическая область | Critical region
Критическая область - критическая область проверки гипотезы - область выборочных значений, при которых нулевая гипотеза отклоняется.
Круговой график
Круговой график - диаграмма, показывающая частотное распределение категориальной переменной. Круг делится на сегменты, площадь каждого пропорциональна частоте категории, к которой он относится.
Кумулятивная частота
Кумулятивная частота - сумма частот всех значений до заданного значения. Если значения x1, x2, ... xn в порядке возрастания, происходят с частотами f1, f2, ... fn f соответственно, то кумулятивная частота xi определяется как f1 + f2 + ... + fi.
Линейный график
Линейный график - линейный график, который упорядочивает данные по реальной линии. Также называется точечным графиком.
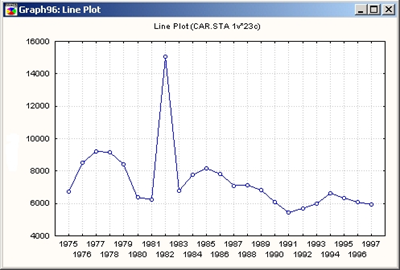
Линия регрессии
Линия регрессии - прямая линия, используемая для оценки взаимосвязи между двумя переменными, основанная на точках участка рассеяния; часто определяется методом наименьших квадратов. Когда линия склоняется вниз (сверху слева направо вниз), это указывает на отрицательную или обратную связь между переменными; когда она наклоняется (снизу слева направо вверх), указывается положительная или прямая связь.
Лог-нормальное распределение
Лог-нормальное распределение - вытянутое вправо распределение вероятности непрерывной случайной переменной, чей логарифм подчиняется нормальному распределению.
Логистическая регрессия, логит-регрессия
Логистическая регрессия предоставляет метод моделирования бинарной переменной отклика, принимающей значения 1 и 0. Например, вероятность того, что посетитель с данными признаками сделает покупку в интернет-магазине. В общем случае решается задача классификации с двумя классами (y=0 или 1, где переменная y указывает класс объекта) в предположении, что вероятность принадлежности объекта к одному из классов выражается через набор признаков этого объекта x1,..., xk.
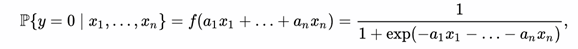
В данном случае мы не можем применить обычную линейную регрессию, так как отклик является категориальным. Для получения оценок проводится логистическое преобразование наблюдаемых частот. Логистическая или логит функция используется для преобразования S'-образной кривой приблизительно в прямую линию и изменения долей в диапазоне -∞ -+ ∞. Определим логит-преобразование наблюдаемых частот определенного исхода формулой:
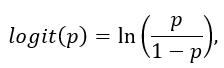
где р есть вероятность исхода.
Заметим, что при р, стремящихся к 0, logit(p) стремится к -∞.
При р, стремящихся к 1, logit(p) стремится к +∞.
Величина p/(1-p) называется отношением шансов (odds ratio) – вероятность наступления определенного исхода, деленная на вероятность не наступления исхода.
Соотношение между вероятностью исхода и значение предиктора х может быть описано линейной моделью: logit (р) = а + bх
Хотя данная модель кажется похожей на обычную модель линейной регрессии, лежащее в основе распределение - биномиальное, параметры a и b не могут быть оценены как в простой линейной регрессии методом наименьших квадратов.
В логит-регрессии параметры оцениваются с помощью метода максимального правдоподобия.
Лог-ранговый критерий
Лог-ранговый критерий - непараметрический подход к сравнению двух кривых выживаемости.
Ложноотрицательный
Ложноотрицательный - пациент, который имеет заболевание, но диагностируется как не имеющий его.
Ложноположительный
Ложноположительный - пациент, который не имеет заболевания, но диагностируется как имеющий его.
Машинное обучение | Machine Learning
Машинное обучение может использоваться для интеллектуального анализа и распознавания образов в больших данных. Машинное обучение «связано с вопросом о том, как создавать компьютерные программы, которые автоматически улучшаются с опытом».
Машинное обучение носит междисциплинарный характер и использует, в частности, методы из областей информатики, статистики и искусственного интеллекта, теории алгоритмов и др.
Основными артефактами исследований машинного обучения являются алгоритмы, которые облегчают это автоматическое улучшение по сравнению с опытом, алгоритмы, которые могут применяться в таких различных областях, как компьютерное зрение, искусственный интеллект и интеллектуальный анализ данных.

Медиана
Медиана - предположим, что наблюдения в наборе числовых данных упорядочены по возрастанию.
Медиана - это среднее наблюдение в выборке, если имеется нечетное число наблюдений, и среднее значение двух средних наблюдений, если имеется четное число наблюдений.
Межквартильный размах
Межквартильный размах - интервал между 25-й и 75-й процентилями; он содержит центральные 50% упорядоченных значений.
Метаанализ
Метаанализ - количественный систематический обзор, который соединяет результаты предыдущих исследований для создания общей оценки интересующего нас эффекта.
Метод наименьших квадратов (МНК)
Метод наименьших квадратов (МНК) - метод оценки параметров в регрессионном анализе, основанный на минимизации суммы квадратов остатков.
Минимальное значение
Минимальное значение - наименьшее значение в выборке.
Множество
Множество - произвольный набор (класс, семейство, совокупность) объектов. Объекты множества являются его элементами. Если объект x является элементом множества А, то говорят, что x принадлежит А.
Существует два способа задания множества. Перечисление элементов, например, A = {1, 2, 3}.
Задание свойства, порождающего множество (set builder notation), например, A = {x: x > 0} – множество всех положительных чисел.
Ключевым является набор элементов и их принадлежность множеству, но не их порядок, поэтому записи {1, 2, 3} и {3, 2, 1} являются эквивалентными.
Множественная линейная регрессия
Множественная линейная регрессия - модель линейной регрессии, в которой имеется одна зависимая переменная и две или более независимых переменных или предикторов.
Мода
Мода - величина, которая наиболее часто появляется в данных. Возможен унимодальный набор данных, бимодальный и тд. Бимодальность часто интерпретируется как неоднородность данных.
Модель математическая
Модель математическая описывает в математических терминах соотношение между двумя или более переменными.
Модель вероятностная
Модель вероятностная описывает в вероятностных терминах соотношение между переменными.
Мощность критерия
Мощность критерия - вероятность отвергнуть нулевую гипотезы, когда она не верна.
Независимая переменная
Независимая (объясняющая) переменная - переменная (обычно обозначаемая как x), которая применяется для прогноза зависимой переменной в регрессионном анализе. Также называется «независимая или переменная может принимать».
Независимое событие
Независимое событие - два события независимы, если результат одного события не влияет на исход другого.
Непараметрический критерий
Непараметрический критерий - критерий проверки гипотез, который не делает предположений о распределении анализируемых данных.
Иногда называется критерием, свободным от распределения.
Непарный двухвыборочный
Непарный двухвыборочный t-критерий: проверяет нулевую гипотезу, согласно которой средние двух независимых выборок равны.
Основан на предположении нормального распределения данных.
Непересекающиеся множества
Непересекающиеся множества - множества не пересекаются, если они не имеют общих элементов.
Например, множества A = {1,2,3} и B = {5,6,7} не пересекаются.
Множества A = {1,2,3,4,5} и B = {5,6,7} пересекаются и имеют общим элементом число 5.
Несмещенная оценка
Несмещенная оценка - для того чтобы оценка была несмещенной, требуется, чтобы в среднем оценка дала истинное значение неизвестного параметра.
Формально оценка X является несмещенной оценкой параметра θ, если E(X) = θ.
Номинальная переменная
Номинальная переменная - категориальная переменная, чьи категории не имеют естественного порядка.
Номинальные данные
Номинальные данные - набор данных называется номинальным, если принадлежащим ему наблюдениям можно присвоить код в виде числа, где числа являются просто метками. Вы не можете упорядочить номинальные данные.
Например, в наборе данных мужчины могут быть закодированы как 0, женщины как 1; семейное положение человека может быть закодировано как Y, если он женат, N, если он одинок.
Номограмма Альтмана
Номограмма Альтмана - диаграмма, которая устанавливает связь размера выборки, мощности статистического критерия, уровень значимости и стандартизированную разность.
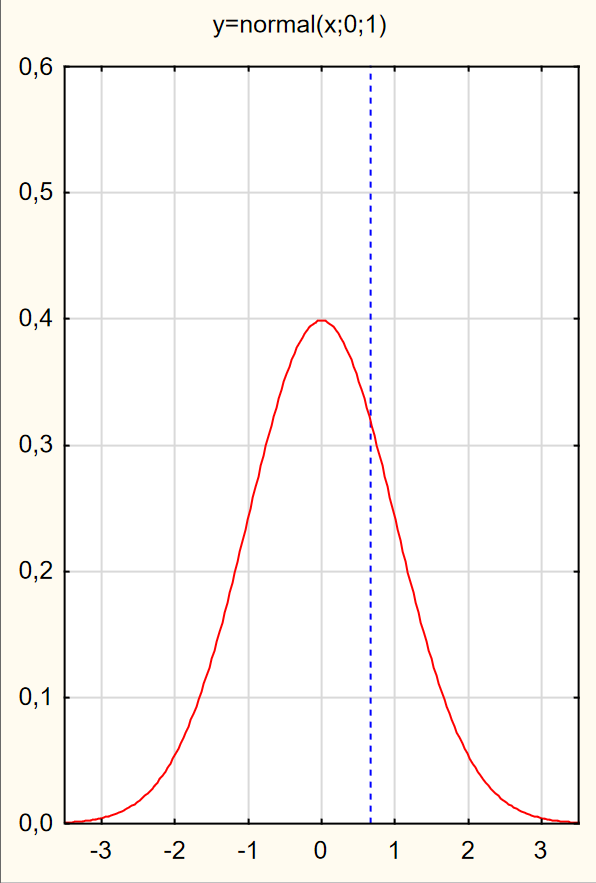
Нормальное распределение
Нормальное распределение - непрерывное распределение вероятностей (с параметрами µ и σ ) функция плотности которого определяется формулой
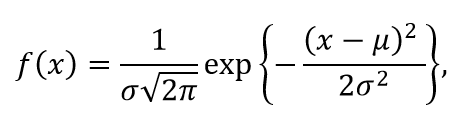
где µ - среднее и σ- стандартное отклонение.
Нормальное распределение симметрично относительно среднего значения µ и имеет колоколообразную форму, расплывающуюся при увеличении σ.
График плотности стандартного нормального распределения, построенный с помощью вероятностного калькулятора программы Statistica:
Облачные вычисления | Cloud Computing
Облачные вычисления или то, что называют облаком, можно определить как вычислительную модель на базе интернета, которая в основном обеспечивает доступ к вычислительным ресурсам по требованию.
Эти ресурсы включают в себя множество вещей, таких как прикладное программное обеспечение, вычислительные ресурсы, серверы и центры обработки данных и т. д.
Поставщики облачных услуг обычно используют модель «оплата по требованию», сервис как услуга, что позволяет компаниям масштабировать свои затраты по мере необходимости.

Это позволяет предприятиям обойти инфраструктурные затраты на установку оборудования и программного обеспечения, что было неизбежно до появления облака.
Обобщенные линейные модели | GLM
Обобщенные линейные модели (GLM) являются естественным обобщением обычной линейной регрессии, в котором ошибка зависимой переменной может не соответствовать нормальному распределению.
Обобщенные линейных модели рассматривают те случаи, когда зависимая переменная Y принадлежит экспоненциальному семейству распределений, которое включает нормальное, биномиальное, гамма, Пуассона и другие распределения.
При этом среднее значение μ распределения Y связано с линейной комбинацией предикторов (независимых переменных) при помощи функции связи g, а именно:
g(μ) = Xβ
X = (x1, x2, ..., xk, 1) – набор длины n+1 (вектор) независимых переменных;
Y – зависимая переменная (также может быть вектором);
μ – среднее величины Y;
β = (β1, β2, ..., βk, α) - набор длины n+1 (вектор) неизвестных параметров;
α – свободный член;
g – функция связи.
Основная идея функции связи состоит в том, чтобы сопоставить среднее значение Y и линейный предиктор.
Объединение множеств
Объединение множеств - объединение двух множеств A и B - это множество, полученное объединением членов каждого набора. Если A = {1,2,3} и B = {2,4,6}, то A∪ B = {1,2,3,4,6}.
Односторонний критерий
Односторонний критерий - альтернативная гипотеза, определяет направление влияния интересующего нас вмешательства.
Однофакторный дисперсионный анализ
Однофакторный дисперсионный анализ - вид дисперсионного анализа, применяемый длясравнения средних двух и более независимых групп наблюдений.
Описательная аналитика | Descriptive Analytics
Эта форма аналитики носит описательный характер, использует описательные (дескриптивные) статистики. Описательная аналитика суммирует данные, уделяя меньше внимания точным деталям каждой части данных и вместо этого сосредотачиваясь на общем рассказе.
Остатки
Остатки - разность между наблюдаемыми и предсказанными значениями зависимой переменной в регрессионном анализе.
Остаточная дисперсия
Остаточная дисперсия - квадрат оценки стандартной ошибки.
Относительная частота
Относительная частота - частота, выраженная как процент или доля общей частоты.
Относительный риск
Относительный риск - соотношение двух рисков, обычно риск заболевание в группе пациентов, подверженных некоторому факторов, делённый на риск пациентов в контрольной группе.
Отношение шансов
Отношение шансов - отношение двух шансов (например, шансы заболевания у пациентов, подверженные или не подверженные влиянию фактора). Часто принимается как оценка относительного риска в исследовании «случай-контроль».
Отрицательное предсказанное значение
Отрицательное предсказанное значение - доля пациентов с отрицательным результатом теста, которые не имеют заболевания.
Первичная конечная точка
Первичная конечная точка - исход, который наиболее точно отражает преимущество новой терапии в клиническом исследовании.
Перекрёстные исследования
Перекрёстные исследования - исследования, в которых каждый исследуемых пациент получает более одного вида лечения, одно за другим в случайном порядке.
Пересечение множеств
Пересечение множеств - пересечение множеств A и B, обозначаемых A 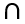 B, является множеством элементы, которые находятся как в A, так и в B.
B, является множеством элементы, которые находятся как в A, так и в B.
Персептрон
Персептрон состоит из следующих основных компонент: входные значения или один входной слой (input layer), веса (weights) и сдвиг (bias), операция суммирования, функция активации (activation function), выход.
На схеме персептрон может быть изображен следующим образом:
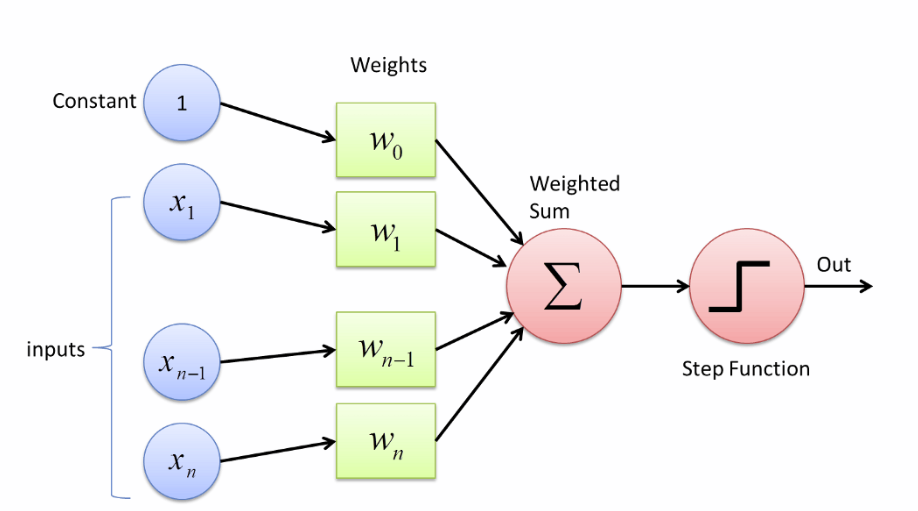
Формально персептроном можно называть также функцию вида:
F = F(x,w) = F(w0 + x1w1 ... + xnwn), где F – функция активации или передаточная функция.
Персептрон (от лат. perceptio — восприятие) воспринимает и передает сигнал, работает по следующей обобщённой схеме: имеются входные значения, которые умножаются на веса, суммируются и подаются на вход активационной функции, которая выдает на выходе значения 0 или 1 в случае ступенчатой функции.
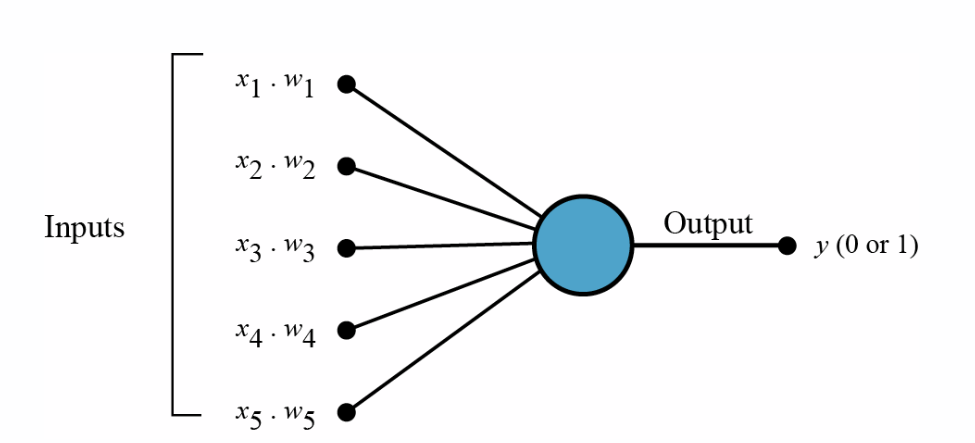
Смещение или порог ступенчатой функции позволяет сдвинуть скачок по оси x.
Эта замечательная модель, предложенная Розенблаттом в 1957 году, описывает функционирование нейронов головного мозга, которые воспринимают и передают возбуждение.
В модели искусственного нейрона возможны различные активационные или передаточные функции: ступенчатая, сигмоидная, гиперболический тангенс и др.
Физический смысл функций активации заключается в усилении слабых и ослаблении сильных сигналов. Если значение сигнала превышает некоторый порог, нейрон возбуждается и передает сигнал следующему нейрону, в противном случае сигнал не передается.
Обычно персептроны используются в задачах классификации, отнесения объектов к одному из двух классов, поэтому называются бинарными линейными классификаторами.
Например, с помощью персептрона мы можем отнести изображения пикселов к одному из двух классов: яркий, темный как показано на следующей схеме:
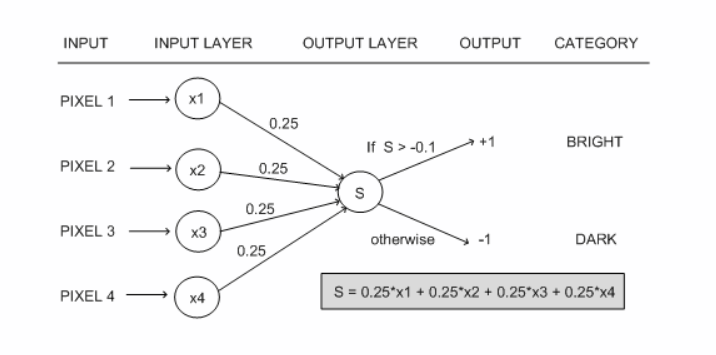
В данном примере на вход персептрона подаются значения яркости 4-х пикселов, которые суммируются с равными весами 0.25 и подаются на вход ступенчатой функции.
Если значение функции активации больше порога -0.1, изображение относится к классу яркий (bright), в противном случае к классу темный (dark).
Формально функция активации описывает гиперплоскость в пространстве (x1…xk), в случае двух входов имеем прямую, при этом возникает линейная классификация, как показано на рисунке ниже:
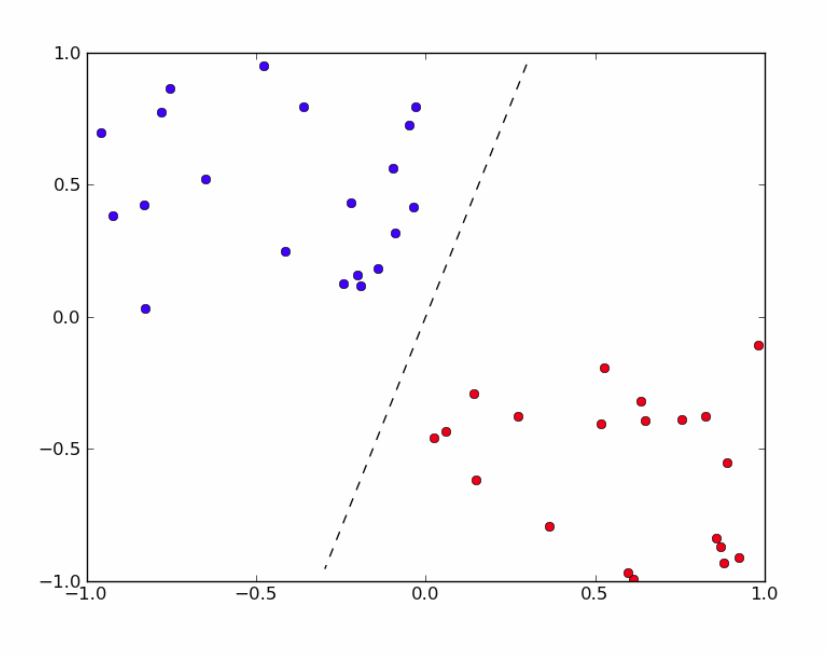
Можно провести градацию изображения по степени яркости, тогда возникает задача мультиклассификации. Для ее решения нужно специальным образом закодировать выходы персептрона.
В моделях персептрона используют следующие функции активации: ступенчатая, сигмоидная, гиперболический тангенс и др.
Сигмоидная функция – это гладкая, монотонно возрастающая функция, имеющая S образную форму:
S(x) = 1/(1+e-x)
S(x) отображает (-∞, +∞) в интервал (0,1).
Важное свойство производной сигмоида S'(x) = S(x)(1-S(x)), позволяющее вычислять производную через саму функцию, используется в алгоритме обратного распространения ошибки.
Сигмоидная функция применяется в нейронных сетях в качестве функций активации, позволяя усиливать слабые сигналы и уменьшать сильные сигналы.
Гиперболический тангенс - это гладкая, монотонно возрастающая функция, отображающая интервал (-∞, +∞) в интервал (-1,1).
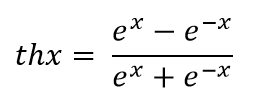
Важное свойство производной гиперболического тангенса th'x = (1+thx)(1-thx), позволяющее вычислять производную функции через саму функцию, используется в алгоритме обратного распространения ошибки.
Подмножество
Подмножество - множество A является подмножеством множества B, если все элементы множества A являются элементами множества B, записывается как A ⊆ B.
Полиномиальная регрессия
>Полиномиальная регрессия - соотношение между зависимой и независимой переменной, описываемое полиномом.
Предсказанное значение
Предсказанное значение - предсказанное значение переменной отклика в регрессионном анализе, соответствующее отдельным значениям независимой переменной или предикторов.
Предпроцессинг
Методы предварительной обработки данных, которые необходимо использовать перед применением алгоритмов машинного обучения, в частности, нейронных сетей.
Основные методы предпроцессинга: чистка данных, удаление выбросов, повторных наблюдений, нормализация, стандартизация значений, применение алгоритмов ближайшего соседа, сокращение размерности с помощью метода главных компонент и др.
Прогностическая или предиктивная аналитика | Predictive Analytics
Прогностическая или предиктивная аналитика включает
разнообразные статистические методы интеллектуального анализа данных, машинного обучения, которые анализируют текущие и исторические факты, чтобы делать прогнозы о будущих или иных неизвестных событиях.
Часто неизвестное событие, представляющее интерес, находится в будущем, но прогнозная аналитика может применяться к любому типу неизвестных событий, будь то в прошлом, настоящем или будущем.
Например, выявление подозреваемых после совершения преступления или мошенничество с кредитными картами в случае его совершения.
Ключевым элементом предиктивной аналитики является выявление взаимосвязей между объясняющими переменными и предсказанными переменными из прошлых событий и их использование для предсказания неизвестного результата.
Используется в бизнесе, маркетинге, промышленности, актуарных и финансовых расчетах, ритейле, телекоммуникациях других областях.

Прогностическая ценность положительного результата
Прогностическая ценность положительного результата - доля пациентов с положительным результатом диагностического теста, имеющая заболевание.
Пуассоновская регрессия
В пуассоновской регрессии предполагается, что зависимая переменная распределена по закону Пуассона
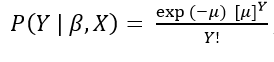
где μ = E( Y | X ) – среднее значение зависимой переменной Y при известных значениях независимых переменных X.
Так как при заданном наборе независимых переменных отклик Y, вообще говоря, является случайной величиной, то точное значение Y получить нельзя, но можно оценить ее среднее значение, которое равно μ.
В качестве функции связи обычно используется логарифм, также степенную и тождественную функцию.
Радиальные базисные функции (РБФ)
Радиальные функции – специальный класс функций, ключевой особенностью которых является то, что их значения убывают монотонно с удалением от центра.
Центр, линейный масштаб и форма радиальной функции являются параметрами модели, которые оцениваются в процессе обучения сети.
Типичная радиальная функция – функция Гаусса, которая в случае скалярных входных данных выглядит так:
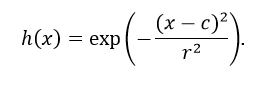
Параметрами функции являются центр c и радиус r.
Нейронная сеть на основе РБФ имеет следующую архитектуру: каждая из n компонент вектора входных данных x соединён с m базисными функциями, выходы которых линейно комбинируются с весами 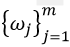 в выход сети f(x).
в выход сети f(x).
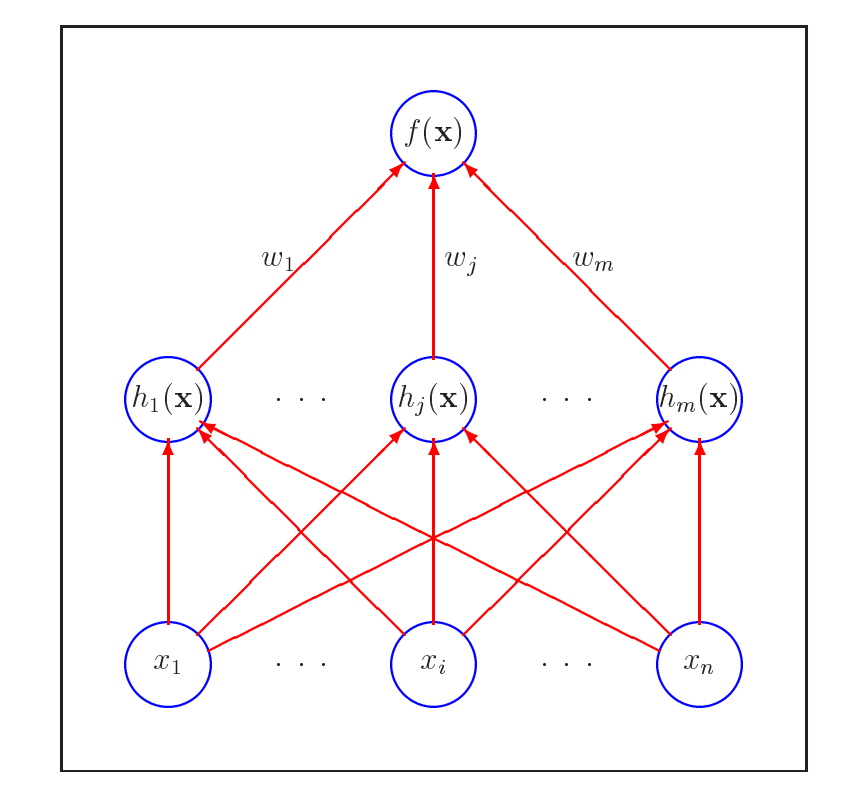
Размах
Размах - разность между наибольшим и наименьшим значениями выборки.
Размер
Размер - это количество элементов в выборке.
Размер выборки является важной величиной, при увеличении размера выборок точность оценок увеличивается.
Однако мы не можем увеличивать размер выборки до бесконечности, так это связано с временными и финансовыми затратами.
Разнообразие Больших Данных | Big Data Variety
Разнообразие относится к типу и характеру данных. Это помогает людям, которые анализируют его, эффективно использовать полученную информацию.
Ранговый коэффициент корреляции Спирмэна
Ранговый коэффициент корреляции Спирмэна - непараметрическая альтернатива коэффициенту корреляции Пирсона, обеспечивает оценку связи между двумя порядковыми переменными.
Рандомизация
Рандомизация - распределение объектов в группы случайным образом, данная процедура предотвращает сдвиг в оценках.
Например, разбиение данных в машинном обучении на обучающую, тестовую и проверочную выборки проводится рандомизированным образом.
Регрессионная модель пропорционального риска Кокса
Используется в анализе данных для изучения одновременного эффекта зависимых переменных на выживаемость.
Репозиторий
Репозиторий (repository - склад, хранилище) хранилище данных, также существуют репозитории для хранения программ, позволяет пользователям находить полезное ПО для решения конкретных задач.
Термин репозиторий данных может использоваться для описания нескольких способов сбора и хранения данных:
- Хранилище данных (data warehouse) - это большой репозиторий данных, который агрегирует данные, как правило, из нескольких источников или сегментов бизнеса без обязательного связывания данных.
- Озеро данных (data lake) - это большое хранилище данных, в котором хранятся неструктурированные данные, классифицированные и помеченные метаданными.
- Витрины данных (data marts) - это подмножества хранилища данных. Витрины данных ориентированы на то, что нужно пользователям и проще в использовании. Витрины данных также более безопасны, поскольку они ограничивают авторизованных пользователей изолированными наборами данных. Пользователи не могут получить доступ ко всем данным в хранилище данных.
- Репозитории метаданных хранят данные о данных и базах данных.
- Кубы данных (dData cubes) - списки данных с тремя или более измерениями, которые хранятся в виде таблицы. Кубы являются обобщением плоских электронных таблиц на три и более число измерений.
Пример, бюджет продаж компании в различных срезах: по продуктам, филиалам, каналам сбыта, отчеты показывают объем продаж и выручку по месяцам.
Ретроспективное исследование
Ретроспективное исследование - исследование, в котором объекты выбраны на основании событий, которые произошли в прошлом.
Сезонная вариация
Сезонная вариация - значение интересующей нас переменной систематически изменяются согласно времени года.
Сериальная корреляция
Сериальная корреляция - корреляция между наблюдениями во временных сериях и наблюдениями, отделёнными между собой фиксированным временным интервалом.
Систематический метод выборки
Систематический метод выборки - выборка отбирается из популяции, применяя некоторый систематический метод, но не метод, основанный на случайности.
Систематический обзор
Систематический обзор формализованный и строгий подход к комбинации результатов от всех уместных изучений подобных исследований по тому же самому состоянию здоровья.
Систематическое размещение
Систематическое размещение - пациенты в клиническом исследовании назначены на лечение систематизированным, а не случайным образом.
Скорость больших данных | Big Data Velocity
Это быстрота, с которой данные генерируются и обрабатываются для удовлетворения требований и задач, которые лежат на пути роста и развития.
Событие
Событие - подмножество пространства выборки.
Например, пространство для эксперимента, в котором дважды бросается монета, определяется {ОО, ОР, РО, РР} и A = {ОР, ОО}, тогда A событие, в котором Орел встречается в первую очередь.
Софтмакс | Softmax
Софтмакс | Softmax - функция Softmax является обобщением логистической функции, используется в машинном обучении для задач мультиклассификации.
Формально имеем:
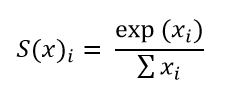
Специфичность теста
Специфичность теста - доля пациентов без заболевания, которые точно идентифицированы диагностическим тестом.
Среднее
Среднее - общий термин для мер положения.
Предположим, что в генеральной совокупности N особей, x обозначает интервал или переменную отношения.
Пусть значения для i-го индивида обозначаются xi. Выборочное среднее значение вычисляется как:
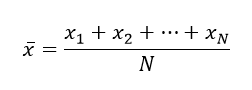
Среднее арифметическое
Среднее арифметическое - мера положения, полученная путём деления суммы значений переменной на число наблюдений, часто называется средним.
Стандартное отклонение
Стандартное отклонение - безразмерная величина, являющаяся мерой рассеяния данных, равна квадратному корню из дисперсии.
Пусть X1, X2, ... Xn выборка из нормально распределенной популяции со средним μ и стандартным отклонение σ > 0.
Тогда выборочное стандартное отклонение равно:
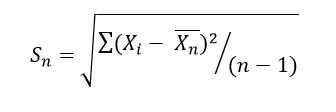
Статистический вывод
Статистический вывод - статистический вывод использует данные из выборки для получения информации о генеральной совокупности, из которой извлечена выборка.
Статистический критерий Вальда
Статистический критерий Вальда - применяется в логистической регрессии для проверки вклада отдельного коэффициента регрессии.
Стационарный временной ряд
Стационарный временной ряд - временная серия, для которой средняя и дисперсия постоянны всё время.
Столбчатая диаграмма
Столбчатая диаграмма - диаграмма, которая показывает распределение качественной или дискретной переменной путём показа отдельной горизонтальной или вертикальной диаграммы для каждой «категории», причём её длина пропорциональна (относительной) частоте в этой «категории».
Страта
Страта - подгруппа данных, внутри которой объекты имеют схожие характеристики, иногда называется блоком данных.
Оценка точечная
Оценка точечная - отдельная величина, полученная на основе данных, которая оценивает неизвестный параметр популяции.
Пусть X1, X2, ... Xn выборка из нормально распределенной популяции со средним μ и стандартным отклонением σ > 0.
Тогда точечной оценкой параметра μ является выборочное среднее
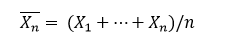
Тогда точечной оценкой параметра σ является величина
Оценка интервальная
Оценка интервальная в отличие от точечной оценки представляет собой интервал (диапазон) значений, в котором с заданной вероятностью лежит неизвестный параметр популяции.
Пусть X1, X2, ... Xn выборка из нормально распределенной популяции со средним μ и стандартным отклонение σ > 0.
Точечной оценкой параметра μ является выборочное среднее
Точечной оценкой параметра σ является величина
Статистика 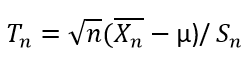 имеет t-распределение с n-1 степенью свободы.
имеет t-распределение с n-1 степенью свободы.
Это позволяет построить 90% доверительный интервал или интервальную оценку для параметра μ:
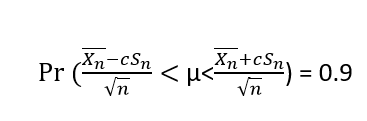
где с – 95% процентиль t-распределение с n-1 степенью свободы.
Тренд
Тренд - значение переменной показывает тенденцию со временем прогрессивно увеличиваться или уменьшаться.
Треугольник Паскаля
Треугольник Паскаля -числовой треугольник с номерами, расположенными в шахматном порядке 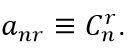 . Начиная с n=0 и r=0,1,..n, это выглядит так:
. Начиная с n=0 и r=0,1,..n, это выглядит так:
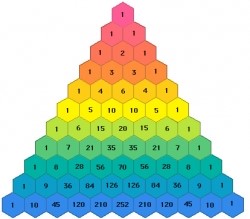
Уровень доверия
Уровень доверия - вероятность того, что доверительный интервал статистики содержит истинный, неизвестный параметр совокупности.
Уровень значимости
Уровень значимости - p-уровень значимости (p-value) соответствует риску совершения ошибки первого рода, отклонения истинной нулевой гипотезы.
Если p< α, нулевая гипотеза отклоняется, часто уровень значимости выбирается как 0,05.
Для принятия решений о том, какую из гипотез (нулевую или альтернативную) следует принять, используют статистические критерии, которые включают в себя методы расчета определенного показателя, статистики критерия, на основании которого принимается решение об отклонении или принятии гипотезы.
Условная вероятность
Условная вероятность - пусть A и B - два события. Вероятность появления А при условии, что наступило событие В называется условной вероятностью A при условии B и обозначается P(A|B):
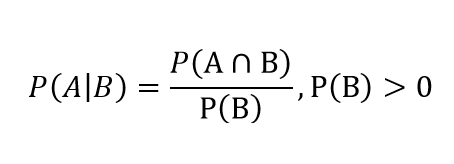
Фактор риска
Фактор риска - решающий фактор, который влияет на частоту исхода, например, заболевания.
Факторный эксперимент
Факторный эксперимент разрешает одновременный анализ ряда интересующих нас факторов.
Форест-график
Форест-график - диаграмма, применяемая в метаанализе и показывающая оценённый эффект в каждом исследовании и их среднее с доверительными интервалами.
Формула Байеса
Формула Байеса - Пусть U1, U2, ..., Un - n взаимоисключающих событий, объединение которых является пространство выборки S.
Пусть A - произвольное событие в S такое, что P(A) ≠ 0. Тогда
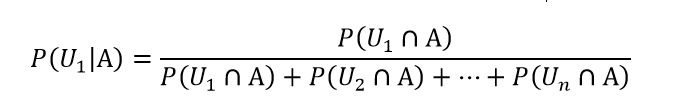
Соответствующие результаты справедливы для всех U2, U3, ..., Un.
В приложениях U1, U2, ..., Un часто трактуются как гипотезы, вероятности которых априорно оцениваются.
При наступлении конкретного события А априорные вероятности пересчитываются в апостериорные вероятности.
В частном случае двух гипотез U и не- U имеет место:
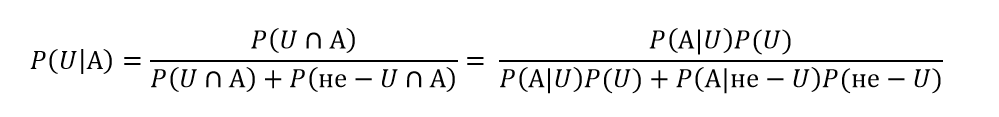
Пример:
А – признак заболевания
U - заболевание
Не-U – нет заболевания
Пусть вероятность заболевания в популяции равна 0.001, формально имеем:
P(U) = 0.001, P(не-U) = 0.999.
Вероятность наличия признака А при условии заболевания P(A|U) = 0.9
Вероятность наличия признака А при отсутствии заболевания P(A|не - U) = 0.01
Тогда по формуле Байеса:
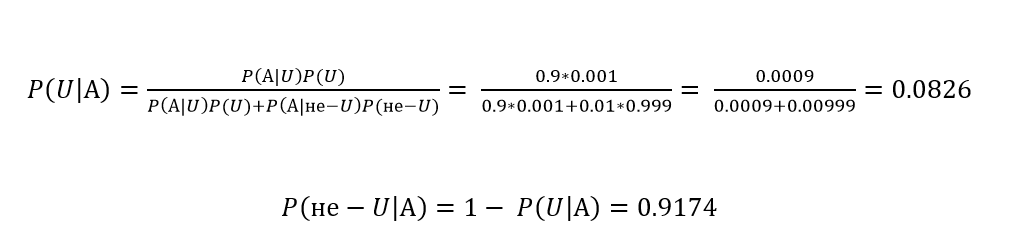
Для уменьшения доли ложноположительных результатов проводится повторное обследование пациентов.
Формула полной вероятности
Пусть U1, U2, ..., Un - n взаимоисключающих событий, объединение которых является пространство выборки S.
S = U1+U2+...+Un.
Тогда имеет место следующая формула полной вероятности, позволяющая выразить вероятность события А через условные вероятности А при условии Ui :
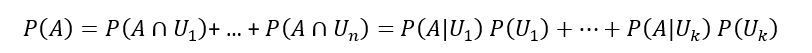
Функции активации в нейронных сетях
В искусственных нейронных сетях как правило используются следующие функции активации: ступенчатая, сигмоидная, гиперболический тангенс и др.
Сигмоидная функция – это гладкая, монотонно возрастающая функция, имеющая S образную форму:
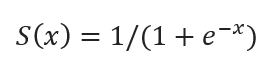
S(x) отображает (-∞, +∞) в интервал (0, 1).
Важное свойство производной сигмоида S'(x) = S(x)(1-S(x)),
позволяющее вычислять производную через саму сигмоидную функцию, используется в алгоритме обратного распространения ошибки.
Сигмоидная функция применяется в нейронных сетях в качестве функций активации, позволяя усиливать слабые и уменьшать сильные сигналы.
Гиперболический тангенс - это гладкая, монотонно возрастающая функция, отображающая интервал (-∞, +∞) в интервал (-1, 1).
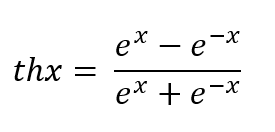
Важное свойство производной гиперболического тангенса th;x = (1 + thx)(1-thx), позволяющее вычислять производную функции через саму функцию, используется в алгоритме обратного распространения ошибки.
Ступенчатая функция (step function) обрезает сигнал: S(x) = 0, если x < порогового значения, S(x) = 1, если x > порогового значения.
Если сигнал превышает некоторое пороговое значение, нейрон возбуждается и передает возбуждение по синапсам другим нейронам.
Хи-квадрат критерий:
используется для проверки гипотезы об отсутствии между факторами в таблице сопряжённости.
Также используется для проверки различий между пропорциями (долями) в данных, проверки однородности.
Хранилище данных | Data Warehouse
Хранилище данных (data warehouse) - это большой репозиторий данных, который агрегирует данные, как правило, из нескольких источников или сегментов бизнеса без обязательного связывания данных.
Хранилище данных обладает следующими характеристиками:
- поддерживаются отдельно от операционных и транзакционных баз данных организации, которые характеризуются частым доступом и используются повседневными организационными операциями;
- позволяют интегрировать различные разрозненные прикладные системы;
- и разрешить доступ к консолидированным историческим данным для обработки и анализа.

Цензурированные (неполные) данные
используются в анализе выживаемости, поскольку имеется неполная информация об исходе лечения.
Также используются в оценке надежности технических систем.
Центральная предельная теорема
Центральная предельная теорема - относится к сходимости распределения нормированных сумм случайных величин.
Распределение среднего от последовательности независимых случайных величин стремится к нормальному распределению, так как число в последовательности неограниченно возрастает.
Самая общая версия состояний ЦПТ:
Пусть X1, X2, ... - последовательность независимых одинаково распределенных случайных величин со средним μ и дисперсией σ2. Пусть
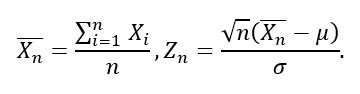
Тогда при увеличении n распределение Zn стремится к стандартному нормальному распределению.
Чувствительность
Чувствительность - доля пациентов с заболеванием, которые точно диагностированы тестом.
Эмпирическое распределение
Эмпирическое распределение - наблюдаемое фактическое распределение данных.
Энтропия | Entropy
Информационная энтропия - это средняя скорость, с которой информация генерируется стохастическим источником данных.
Мера информационной энтропии, связанной с каждым возможным значением данных, является отрицательным логарифмом функции вероятности каждого значения.
Формально имеем:
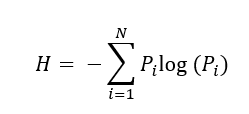
В этой формуле логарифм берется по основанию 2.
Предположим, бросается монета, которая с вероятностью 0,5 выпадает решкой, с вероятностью 0,5 гербом.
В данном случае число исходов N = 2, вероятность каждого исхода P1=P2=0,5.
Энтропия неизвестного результата очередного броска монеты равна 1.
Пусть P1 = 1, P2 = 0, тогда энтропия результата равна 0.
График энтропии для процесса подбрасывания монеты имеет вид:
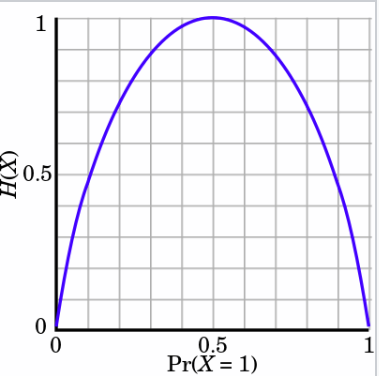
При подбрасывании монеты максимум неопределенности находится точке Р = 0,5.
Ящик с усами
Ящик с усами - диаграмма, построенная из набора числовых данных, в центре которой находится медиана, по сторонам ящика – квартили, далее максимальные и минимальные значения.